1. 引言
机械臂在执行抓取操作时需要获取目标的精确位置姿态,目前主流的位姿生成方法主要是通过数据驱动方法 [1] [2] [3] 来推理各类场景下的目标抓取姿态 [4] [5] [6] 。首先获取场景的点云数据,通过深度神经网络模型对点云特征 [7] 进行分析,最终输出抓取姿态。然而,在非结构化或者混乱的场景中为多个对象生成稳定可靠的抓取姿态仍然是一个挑战 [8] 。近年来,一些抓取姿态检测方法应用物理分析来评估抓取姿态的质量,阮国强等人 [9] 提出将抓取变成4自由度的问题处理,力闭合 [10] 作为主流的评估指标,尽管被许多作品引用,但这种评估方法仍然存在局限,比如仅通过评估摩擦系数提供二元结果,并且生成的置信度分数排名较为离散,这会导致不同的抓取姿态在现实中实现不了一样的抓取表现,然而力闭合度量仍然分配相同的置信度分数,这种现实世界的抓取成功率和置信度分数之间的差距会影响抓取评估网络的性能。除此之外,仅用力闭合单个物理特征在遇到新物体或者复杂场景时缺乏泛化性和鲁棒性,导致抓取姿态无法成功生成。
为了解决上述问题,我们提出了一种混合物理度量检测方法,利用更全面的物理信息来细化置信度分数,基于二指夹爪与物体的接触点,我们采用4个评估指标,分别是力闭合、平面度、重心分布和碰撞扰动。第一个是已有的力闭合指标,他主要衡量夹爪抓取时被抓取物体的稳定性,第二个是平面度指标,目的在于衡量接触点的平整程度,第三个是重心分布指标,为抓取选择一个更加合理的位置,降低因为重心偏移而导致抓取失败的情况,第四个是碰撞扰动指标,主要用于防止抓取末端与接触点可能发生的碰撞。
除此之外,我们还设计了一个前置–后置联合网络,在训练过程中,将上述混合物理度量形成的置信度分数传递到不同的损失函数当中,比如接近方向或者旋转角预测。我们将抓取任务分为前置任务和后置任务,前置任务包括场景置信度分数预测,通常需要的是场景和对象信息,后置任务主要是旋转角度和深度预测,更加关注的是对象和点集信息,基于PointNet++的分层特征学习 [11] ,我们为前置任务提供了低分辨率点集特征,为后置任务提供了高分辨率点集特征,并且加入了一个局部注意力模块,收集更加精确的局部区域信息。最后,为了更好地适应混合物理度量,提出了新的损失函数,使之更好地回归置信度分数。
我们在GraspNet-1Billion数据集上实现了混合物理度量,并且获得了更加精确的抓取置信度分数,我们提出的前置–后置联合网络在新的抓取置信度分数下取得了更好的性能。
2. 抓取姿态表示方法
我们使用
来定义一个完整的6-Dof抓取姿态,其中,
表示夹爪中心点的笛卡尔坐标,
表示夹爪的接近向量,
表示夹爪沿z轴的旋转向量,w表示夹爪的抓取宽度,q表示抓取质量分数,范围在0~1之间,抓取姿态表示见图1。
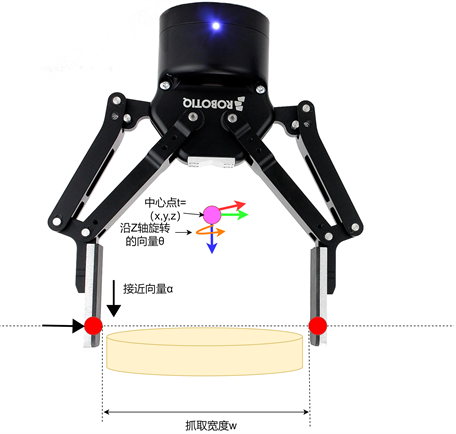
Figure 1. Grasping pose representation method
图1. 抓取姿态表示方法
3. 抓取策略
面对由多个物体所组成的复杂场景,本文使用三维点云数据作为输入并生成相应的抓取姿态。由于需要对场景的点云信息进行特征提取,我们采用PointNet++网络作为主干网络,并提出了一种前置–后置联合网络抓取姿态估计算法,该算法获取目标抓取姿态的每个抓取信息元素,首先将抓取预测解耦为多个任务,分别为深度、宽度、接近方向向量和内部旋转向量的预测,整体抓取策略见图2。前置任务主要考虑场景整体的几何结构,对场景整体进行分割,完成对接近方向向量的预测,后置任务则主要是对于局部区域的预测,主要有深度、宽度、内部旋转向量。因此,我们设计了一个多分辨率处理架构,网络由一个基本主干网络PointNet++和两个分支组成。PointNet++用于提取分层点集特征,低分辨率点集特征传入前置子网络分支中进行场景分割和像素级置信度分数回归,高分辨率点集特征传入后置子网络分支,其中引入了一个局部注意力模块学习更多局部特征,得到一个联合置信度分数,对比以往的单一置信度分数最大值回归,这种方法让预测得到的置信度分数更加精细,我们所设计的联合学习损失函数也更好地适应混合物理指标。
3.1. 局部注意力模块
深度、宽度和内部旋转向量预测通常取决于对象模型的局部几何结构,为了提取更加丰富的局部信息,我们引入了一个局部注意力模块用于查询高分辨率特征图中的局部区域信息,并且通过内部的自注意力单元 [12] 不断学习更新,注意力模块结构如图2所示。首先使用柱面区域查询在高分辨率点集P1中搜索点集P2的邻近点,分别输出点特征和点坐标,然后点特征与点P2和点坐标之间的偏移连接起来,连接后的特征将会通过自注意力层处理,以此增强局部区域注意力。自注意力层专注于获取局部上下文信息 [13] ,这些组特征最终沿着K维通过最大池化保留最显著的特征,通过局部注意力模块获得了空间邻近点的特征和坐标,更好地完成了内部旋转量和深度信息的分类任务。
3.2. 损失函数
对于前置任务的损失函数,我们采用分类损失来学习对象掩码,采用视图分数的回归损失来监督接近方向向量学习,损失函数如下:
(1)
其中,
是个二进制标签,如果像素点属于物体,则为1,反之为0,
是在每个接近方向上使用最大抓取得分的视图得分标签,
、
便是对应的预测值,N = 1024,V = 300。
对于后置任务,我们对获得的48个抓取分数进行回归,这些分数对应12种旋转类型和4种深度类型组成的48个抓取建议,同时,我们通过分类损失来预测内部旋转向量和深度,抓取宽度沿着预测旋转类别进行回归,损失公式如下:
(2)
其中,
等同前置任务损失
,
是前置任务子网络分支预测的俯视方向上的48个候选分数标签,
则是12个内部旋转向量中抓取分数的最大值,
则是4个深度中抓取分数的最大值,
是
方向抓取姿态的抓取宽度,
分别代表对应的预测值,A = 12,D = 4,我们设置
。
最终,总体联合损失函数L如下:
(3)
其中,我们设置
。
4. 抓取评估分数设置
为了更好地对上述得到的抓取姿态进行抓取质量评估,预测不同抓取姿态的置信度分数,在使用力闭合指标的基础上,我们进一步采用3个评估指标,分别是平面度、重心分布和碰撞扰动 [14] ,在GraspNet-1Billion数据集上生成了更加准确的置信度分数。
4.1. 平面度指标
夹爪与物体的接触区域越平坦,抓取质量就越高,因此,我们需要对接触面的平面度进行量化。首先计算物体3D网格模型中点的平面度,利用查询点局部法向量的相似度可以来计算点的平面度得分,用
表示,使用K-近邻法线与查询点法线之间的余弦距离来计算;其次,还要考虑接近方向与接触区域的垂直度,使用余弦距离来计算接近方向向量与接触点法线的一致性,以此作为一致性得分
,通过上述两个得分乘积得到最终平面度分数
,公式如下:
(4)
(5)
(6)
其中,
是查询点的法向量,
是其相邻点的法向量,K是相邻点的数量,
是接近方向向量。
4.2. 重心分布指标
抓取点越靠近物体重心,抓取就越稳定,我们采用抓取点连线到重心之间的欧氏距离作为重心分布得分
:
(7)
其中,
分别表示左接触点、右接触点和重心的坐标。为了让分数为正值,将
进行归一化。
4.3. 碰撞扰动指标
在实际抓取中,当夹爪末端靠近物体时很容易与物体发生碰撞而产生扰动,导致抓取质量下降,因此,为了控制好夹爪末端与物体的距离,我们将夹爪末端与物体接触点之间的欧氏距离最小值作为碰撞扰动分数
:
(8)
其中,
是夹爪左端点和右端点的坐标。为了让分数为正值,将
进行归一化。
4.4. 混合物理指标
混合物理指标是基于力闭合和上述平面度、重心分布、碰撞扰动指标的组合,由于采用了不同的物理指标,我们所提出的指标拥有更好的泛化能力和鲁棒性。最终抓取置信度分数S如下:
(9)
我们将
分别设置为0.6、0.2、0.1、0.1。
5. 实验
5.1. 平台搭建
实验环境见图3,使用安川MA2010机械臂,RealSense D435i深度相机,Robotiq 2F-140二指夹爪,网络训练和评估使用的数据集为GraspNet-1Billion抓取数据集。实验所使用的硬件平台的CPU为Intel i5-13600kf 5.1 GHz,GPU为Nvidia GeForce RTX 3090;软件环境为CUDA 10.2。
5.2. 评估指标
我们使用GraspNet-1Billion数据集,并且采用与文献 [14] 相同的评估标准。首先使用非极大值抑制和碰撞检测过滤提取出排名前50的抓取候选并查询他们的真实置信度分数。设定摩擦系数
并且计算在
条件下的平均预测值,记为
。
取(0, 0.1, 0.3, 0.5, 0.7, 0.9),计算所有
的平均值,记为mAP。
5.3. 对比实验
利用混合物理指标 [15] 生成的新置信度分数,我们输入到不同网络中,实验参数设置均相同,我们所提出的网络模型与其他模型对比的实验结果如下所示。模型1为文献 [16] 中的方法,模型2则为本文设计的方法,实验结果对比见表1,相较于模型1,本文设计的模型在mAP方面均有所提升。

Table 1. Comparison of the experimental results between the different models in the dataset
表1. 不同模型在数据集中的实验结果对比
5.4. 单物体场景抓取实验
为了验证我们所提出的抓取检测方法的性能,首先进行了单物体抓取实验,选取不同的10种物品进行测试,每种物品进行30次实验,每次实验的摆放位置和姿态都会进行改变,模型1、2的实验对比结果见表2,可视化场景见图4。实验结果表明,我们所提出的抓取检测方法在抓取成功率上总体优于目前较为先进的抓取检测方法。
Table 2. Results of single-object scene grasping experiments
表2. 单物体场景抓取实验结果

Figure 4. Single-object scene grasping experiment
图4. 单物体场景抓取实验
5.5. 多物体场景抓取实验
为了验证所提出的抓取检测算法在多物体的复杂场景下的抓取性能,我们进行了多物体场景下的抓取实验。一共设置了6种场景,每种场景放入5个不同物体,对每个场景进行了10轮抓取测试,每轮测试的物品摆放位置和姿态都不同,并且计算每轮抓取的抓取成功率,每次抓取尝试以最后将10轮测试的抓取成功率取平均值得到每个场景的抓取成功率。模型的对比实验结果见表3,抓取场景的可视化结果见图5。对比结果显示,我们所设计的抓取检测方法在多物体场景下的总体抓取率相比模型1提升。原因在于前置–后置联合网络充分考虑整体和局部的关键信息,并且借助多种物理度量提升抓取成功率。
Table 3. Results of multi-object scene grasping experiments
表3. 多物体场景抓取实验结果

Figure 5. Multi-object scene grasping experiment
图5. 多物体场景抓取实验
6. 结论
我们提出了使用混合物理度量评估6-Dof抓取检测的抓取质量并且在GraspNet-1Billion数据集上生成了新的抓取置信度分数,旨在提升机械臂在面对大小不同、形状不同等场景干扰因素下生成精确抓取质量分数的问题。同时,还提出了一个基于PointNet++网络改进的前置–后置联合网络来更好地使用新的置信度分数以准确生成抓取姿态。本文提出方法既可以直接对复杂场景进行整体的抓取估计,也可以实现不同物体的精确抓取估计。通过真实环境的抓取实验表明,我们所提出的混合物理度量和多级网络提高了抓取的成功率,并且在不同的场景和面对不同的对象都具有很好的鲁棒性和适应性。本方法可应用于工业机器人的抓取任务,接下来的工作需要搭建机器人抓取平台进行实验应用,以验证算法的泛化性。