1. 引言
近年来,语义web [1] 成为了目前主要的学术研究之一,在语义web的基础之上许多关键技术都能更进一步发展,语义web的目的不仅仅是简单的提取原始数据,而是将数据连接在一起,利用添加元数据的方法来使机器理解数据概念和不同数据间的逻辑关系 [2] [3] 。同时将现实世界中的各种概念和实体以结构化的形式进行表达,让机器也明白数据的语义以及数据之间的关系。
关系数据库是当前使用的最为广泛的一种数据库,各方面都具有很好的优势,但因为数据欠缺一定的语义能力,所以要把关系数据库转换为具有语义的资源描述框架,因此研究将关系数据库转换为资源描述框架有很好的研究价值。
目前对于将关系数据库转换为资源描述框架的研究有很多,比较多采用的方法是W3C提供的DM [4] (直接映射)和R2RML映射语言,其中R2RML是推荐标准,但这个方法需要手工编辑映射过程 [5] ,并掌握和使用各种映射工具和映射语言,还需对本体模型和数据库结构等特别熟悉 [6] [7] [8] [9] 。目前的传统方案所使用的映射方式实现的效率并不佳,甚至未能达到预期效果 [10] [11] [12] [13] ,此外很多的转换方法是将整个关系数据库直接转换为RDF格式 [14] [15] [16] ,这样会造成占据存储空间大,转换效率低的问题,还需要对关系数据库间的模式信息进行进一步的分析并提取,来保证转换的数据的语义保持能力 [17] ,所以本文提出了新的方法——基于RDB-RDF模式映射的数据转换方法从而实现关系数据库到资源描述框架的转换。
本文避免了数据的全部转储,采用对用户的每个SPARQL查询转换为SQL查询的方式查询关系数据库并提取RDB数据的方法。此外,在转换时将实例和模式的关注点分离开来,先利用二者形式化定义来完成基础的模式映射,并在映射过程中引入映射描述,从而简化转换过程。数据物化和按需映射相结合,逐步完成数据物化。
2. 相关概念
关系数据库(Relational database):实体和实体之间的联系的集合能够构成一个关系数据库,用行和列组成的二维表去管理数据,执行具体操作时使用SQL来实现。
RDF(S):即元数据模型RDF (Resource Description Framework)和RDF模式(RDF Schema,简称RDFS),能够在Web中描述任何有用信息,并且能够为这些信息赋予确定的语义。
数据物化:数据物化是将静态源数据库转换为RDF表示的过程。描述了如何通过属于映射和三重映射将关系数据库转换为RDF。生成的RDF知识库可以在三重存储中物化,然后用SPARQL进行查询 [18] 。
按需映射:按需是动态的,只需要考虑当前的SPARQL [19] [20] 查询,只涉及SPARQL查询中指定的三元组的数据 [21] 。
3. 基于RDB-RDF模式映射的数据转换方法
为了更好的保留数据的完整语义信息,更好的完成整个映射过程,本节通过关系数据库以及RDF(S)的显著特点,提出二者对应的形式化定义。
3.1. 形式化定义
3.1.1. 关系数据库的形式化定义
关系数据库模式由关系模式(表的结构)和完整性约束两部分组成。在关系数据库模式这个内容中,实体和实体间的联系都是用关系来表示,关系模式定义了关系(表)的结构、属性(字段)及其数据类型等完整性约束的定义。
定义1:关系数据库模型可以用一个四元组来表示
。
B表示关系数据库中的基本概念的有限集。
,Tab表示的是关系数据库中的所有数据表有限集。Col代表数据表中字段的有限集。D表示数据类型的有限集。
C表示关系数据库中约束关系的集合。
, Pcons表示所有主键约束的集合,Fcons表示外键约束的有限集,Ucons表示所有唯一约束的有限集,Ncons表示所有非空约束的有限集。
Inh表示关系数据库中继承关系的有限集,
,其中SingleI表示所有单继承关系的集合,MultiI表示所有多继承关系的集合。
Ins表示数据库中所有数据表存储实例数据的集合。
3.1.2. RDF(S)模型的形式化定义
RDF语句由RDF声明构成,每个声明由主语、谓语和宾语这样的三元组的形式表示。RDF Schema是一种轻量级的本体语言,能够提供具有固定含义的建模语言,包括类和子类、属性和子属性、定义域和值域等约束情况。RDF(S)的形式化定义如下。
定义2:资源描述框架模型可以用一个三元组
来表示。
RB表示的是RDF(S)所有基本属性的有限集,
。RC表示了RDF(S)中的所有类,RD表示所有基本数据类型,RP表示所有属性的集合。
RA表示RDF(S)中的公理集合,是由两两不相交的集合来组成的。
,类公理CAxiom集中包含了本体中定义的所有类公理;属性公理PAxiom集中包含本体中定义的所有属性公理。
RI表示所有实例的有限集。
全篇的关系数据库以房地产对象关系数据库为依据,关系数据库中存储的数据表结构如图1所示。builds表为建筑物盘,包含建筑物盘号Id、开发商builderCom和项目名称projectName;build表为楼栋,包含楼栋号Id、盘号buildsId;project表为项目表,包含项目号Id、开发商builderCom、项目名称name和项目日期date;builder表为开发商表,包含开发商Company和开发商所在地址town;state表为房屋状态表,包含房屋号Id和房屋状态roomstate;takebuilds表为关联关系表,buildsId和builderCom是该表的主键也是外键,作为外键分别指向表builds的主键和表builder的主键;house表为房屋表,包含房屋号Id,房屋地址addr和房屋楼层floor;图中虚线框中的内容为house表的继承关系,分别为commercial_house、residential_house和public_rental_house。Commercial_house表代表商业房,包含房屋号Id,房屋收益earnings和房屋用途use;residential_house代表住宅房,包含房屋号Id和房屋产权property_right;public_rental_house为公租房,包含房屋号Id,房屋居住权residence和房屋补贴subsidy。
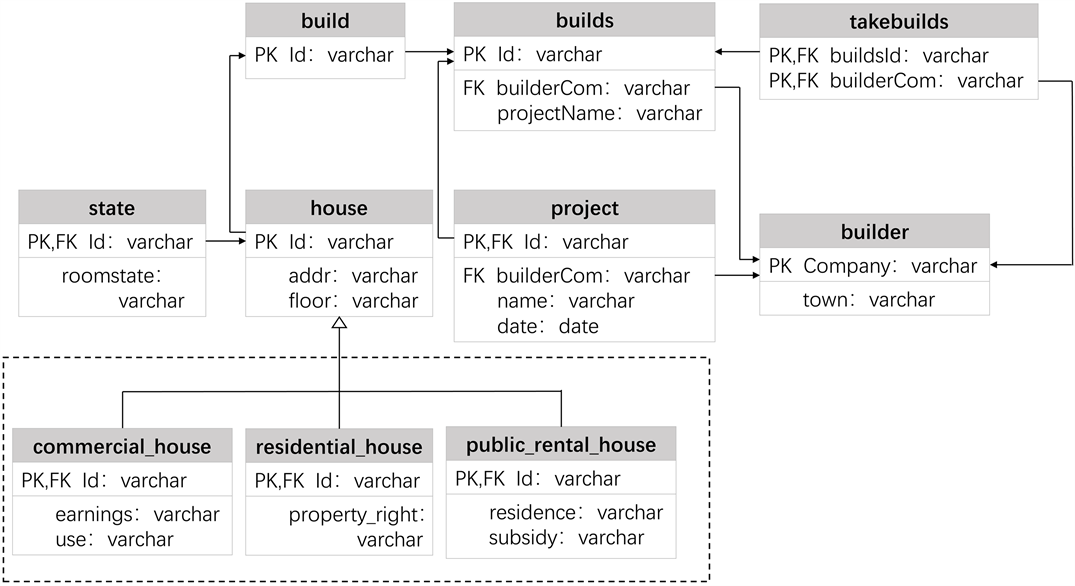
Figure 1. Structure of relational database
图1. 关系数据库的结构图
3.2. 模式映射
整个系统的映射过程分为模式层面和实例层面进行转换,首先介绍模式层面的映射情况。
3.2.1. RDF Schema的构建规则
根据关系数据库和RDF(S)的形式化定义以及提取到的语义信息,提出构建RDF Schema的详细规则。在本节中RDF(S)模型利用提出的三元组
表示,关系数据库模型用
表示,
表示映射过程。
规则1 (基本实体表映射):
对于数据库中任意一个基本实体表可以直接映射成为RDF Schema 中类。如图1中的builder表可以直接映射成为RDF Schema中的类,映射结果为:
规则2 (继承关系映射):
AND
AND
AND
对于任一包含单继承或者多继承关系的实体表,映射时需要保留数据表包含的继承语义。以图1中commercial_house表为例,该表是house表的子表。则保留继承语义时先按照规则1创建父表,再创建子表,并将子表与父表按照继承关系进行连接,映射结果为:
规则3 (基础数据类型映射):
AND
如果数据表中的字段类型是基础的数据类型,那么这个字段就映射成为RDF(S)中的数值属性,这个字段映射后的定义域为字段所在的数据表映射成为的类,值域为字段的数据类型。以builder表中包含的Company属性为例,该属性的数据类型是基础数据类型。映射结果可以表示为:
规则4 (引用关系表映射):
AND
AND
引用表中包含外键约束的字段,可以看作是两个实体间的聚合关系。映射时可以将外键约束所在字段映射成为对象属性。例如builds表中的builderCom字段是该表的外键,指向表builder的主键,这时就将builder作为builderCom属性的属性类型,映射结果如下:
规则5 (关联关系表映射):
关联关系表达两个实体之间的关系,没有单独拥有的字段,所以直接映射成为对象属性。如takebuilds表,该表将不被映射成为RDF Schema类,而是将其映射成为RDF Schema中的对象属性,表达两个实体间的联系。外键引用的表即为该属性的定义域和值域,映射结果如下:
3.2.2. RDF Schema图的构建
接下来提出将关系数据库模式转换为RDF图的形式。RDF图是以三元组的形式显现出来的,所以在关系数据库映射为RDF图的过程中,将满足以下映射规则(图2为映射规则的图式情况):
1) 数据库名称映射到命名空间。数据库的名称映射到RDF名称空间;
2) 表名映射为主体。RDB表的名称映射到RDF主体;
3) 列映射为谓词。RDB表中的列映射到RDF图中的谓词;
4) 列值作为对象。Table.column的单元格映射到RDF图的对象;
5) 行作为实例。RDB 表中的每一行都映射到其相应的RDF三元组。
谓词类型:要建立表之间的关系,需要同时使用主键和外键,有些情况下,表之间的关系没有明确指定,而是隐含为概念模式。根据谓词的功能,他们被分为属性谓词和链接谓词两种。整个关系数据库中的部分数据信息如表1(a)~(i)所示。
1) 属性谓词:表示基本概念,并包含以值项表示为TableName.Ci的文字值。例如,builds.Id表示属性谓词,其中builds是基元表,Id是表1(a)中表示列的标题。
2) 链接谓词:链接谓词派生自外键和主键关系。根据目标表的不同,链接谓词分为内部链接和外部链接。内部链接谓词用于递归关系,而外部链接谓词用于不同的表。链接谓词的对象值将连接表达式表示为TableName.Ci = TableName.Cj。
(a) Builds
(b) Build
(c) House
(d) Project
(e) Builder
(f) State
(g) Commercial_house
(h) Residential_house
(i) Public_rental_house
根据上述规则以及关系数据库结构,可以将RDB的结构映射成为RDF图的关系图,整体的关系图如图3所示。在模式层次上,不引入复杂的结构,生成这样的概念模式图。链接谓词借助于属性谓词中虚线包含的关系表达式(后称为连接表达式),有效地解决了许多复杂的映射问题,例如外键关系。根据链接谓词而引入的连接表达式使得原有的隐式实现的外键关系显示的表示出来,有助于解决RDB到RDF映射期间产生的各种复杂的问题。
映射描述:关系图3显示了RDF关系图的所有的映射信息,包含各数据表之间的联系,根据外键的联系产生的数据表之间的关系。映射描述其实就是对数据库映射情况的具体解释,将数据表之间的联系用表达式的形式展示出来,便于后续查询转换的理解使用。具体的表之间的映射描述如表2(a),表2(b)所示。
(a) Column mapping (b) Relation mapping
(b) Relation mapping
Table 2. Mapping description table
表2. 映射描述表
映射描述在SPARQL到SQL的转换中如何发挥作用可通过实例表明,例如,一个用户提出了一个问题,“秀水花城项目所创设的开发商地址在哪里?”,对于这个问题生成SPARQL查询转换为SQL查询时,如图4所示。由于模式层面映射,从RDF关系图找到对应的查询模式图,构造SPARQL语句很容易,接着借助映射描述表中的谓词含义,“秀水花城”作为name分别具有对象值术语project.Name和链接谓词create代表的连接表达式project.builderCom = builder.Company。在一个序列中,谓词名称介于?p和?o被推导为builder.Town,这样的过程就能够生成SQL语句。

Figure 4. SPARQL converted to SQL instance
图4. SPARQL转换为SQL的实例
连接表达式以高效和简单的方式促进复杂表关系的规范化,以便进行数据库管理。总体来说,映射描述很容易实现,因为有映射描述,所以将SPARQL转换为SQL的过程将会变得简单容易实现。
3.3. SPARQL to SQL
要实现按需映射,动态地生成RDF数据,就需要将每个用户提出的问题从SPARQL查询的形式转换为SQL查询语句,作用于RDB上。首先分析SPARQL查询语句,将查询语句中的三元组模式提取出来,获取到查询语句的主体、谓词和对象,接下来用上文定义的映射描述,将SPARQL转换为SQL,作用于RDB数据上,从而能够在RDB数据中得到想要的数据信息,将得到的数据利用数据物化转换为RDF三元组格式,并存储在三元存储库中,这样就得到了RDF数据,再将SPARQL查询重新运用在此三元组数据上,就能得到想要的最终查询结果。按需映射只需要一段信息,就能将SPARQL查询转换为SQL查询。算法SPARQLtoSQL具体实现过程如下:
3.4. RDB-RDF转换算法
系统提出了基于RDB-RDF模式映射的数据转换方法,整体思路为从一个空的RDF三元组存储开始,对每个用户提出的SPARQL查询,首先将这个SPARQL查询应用到三元组存储库上,若没有答案,则说明目前是空状态,可以开始整个映射流程。我们借助映射描述,引入连接表达式,生成包含SPARQL查询中指定的三元组的SQL查询,将这些查询应用于RDB,并将回答的RDB数据转换为三元组,我们将这些三元组存储在三元存储库中,最后,再对此三元存储库重新应用SPARQL查询,从而得到最终答案。在这个过程中,数据物化是逐步完成的,也避免了数据全部转换,而且需要存储的数据也大幅减少。也因为有连接表达式的存在,使得SPARQL向SQL的转换更加灵活简单。全文的主要贡献是避免了数据的全部转储,用到的是部分转换而不是整个数据转换。图5说明了基于模式的RDB-RDF映射的系统结构设计。
在转换过程中,每次的查询转换都是基于最新的RDB数据,也解决了传统方法转换时RDB数据更新造成的数据延迟问题。整体实现如算法2所示:
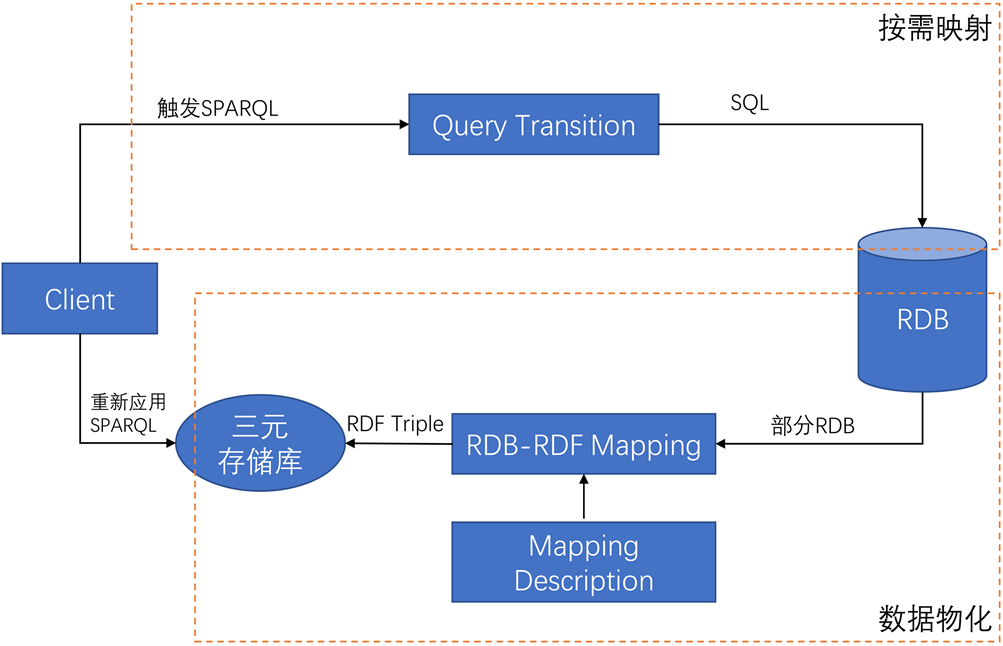
Figure 5. RDB-RDF mapping system architecture diagram
图5. RDB-RDF映射系统架构图
4. 实验评估分析
在提出基于RDB-RDF模式映射数据转换的方法之后,需要对算法的整体效果进行评估,从性能分析和语义保持两个方面对构建的方法进行评估。
4.1. 数据集
本系统选用了关系数据库(扩充了对象关系数据库)作为构建实验的数据库。选取的数据集是具体的房地产数据集,经过一系列的清洗筛选最终得到实验所需的数据集。利用该数据集建立了三个不同规模的数据源。表3给出了三个数据源的详细信息。表中的每一列代表相应数据表中的数据的数量。
Table 3. Information on the number of data sources selected for experiments
表3. 实验选取数据源数量信息
4.2. 性能分析
4.2.1. 构建RDF(S)所用时间
设置了三个不同规模的数据源,分布构建RDF(S),记录不同数据源构建得到RDF(S)所花费时间。对每个数据源都进行多次构建实验,然后多次所得时间的平均值进行记录,最终得到不同规模数据源构建RDF(S)所用时间如图6所示。
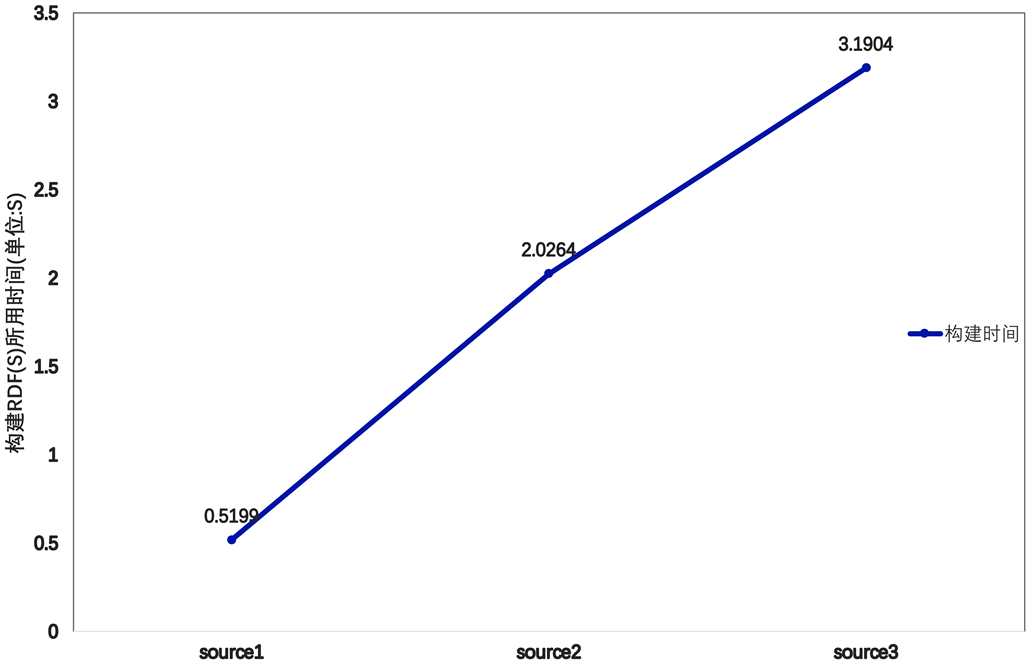
Figure 6. Time spent on building RDFS by RDB-RDF approach
图6. RDB-RDF方法构建RDFS花费时间
4.2.2. 对比分析
将传统的方法(直接映射DM和R2RML)与提出的基于RDB-RDF模式映射的数据转换方法对不同规模的数据源的构建过程所用时间进行对比,得到的结果如表4所示。图7为不同方法对于不同数据源构建所用时间的折线图,直观地看出本文提出的方法节省了时间,比传统的方法耗时少。
4.3. 查询结果对比
本文的方法不仅能实现将关系数据库转换为资源描述框架,还能实现传统的方法(直接映射DM和R2RML)无法实现的将对象关系数据库转换为资源描述框架,对关系数据库进行了扩充,实现了这种转换,并且实验表明,这种转换方法能够实现这二者的无损转换。
Table 4. Comparison of data conversion time
表4. 数据转换时间对比

Figure 7. Comparative analysis of time spent on data conversion by different methods
图7. 不同方法数据转换所用时间对比分析
所以为了检验这个映射过程是否成功将关系数据库和对象关系数据库成功映射为RDF实例,需要对关系数据库中包含的实例数据与映射得到的RDF(S)文件中包含的实例信息进行对比。所以本文从不同的查询角度出发设计多组查询条件,对映射得到的实例与关系数据库中的存储的实例数据进行对比。本文设计了一组等价的SPARQL查询和SQL查询,分别施加在生成的RDF文档和原关系数据库上来判断数据转换的准确性。设计的查询条件如下:
1) 对于基本实体表中实例数据的映射情况进行检验
Q1:SELECT Company,Town FROM builder;(查询开发商名称与地址)
2) 对继承实体表中实例数据的映射情况进行检验
Q2:SELECT COUNT(Id) FROM public_rental;(查询public_rental表中有多少房屋)
3) 对引用关系表中实例数据的映射情况进行检验
Q3:SELECT project.Name FROM builder
JOIN project ON builder.Company = project.builderCom
WHERE builder.Company = '沈阳富景房产开发有限公司';(查询沈阳富景房产开发的项目名称是什么)
Q4: SELECT state.roomstate FROM state
JOIN house ON house.Id = state.Id
WHERE house.Id = 3712971;(查询房屋号为3712971目前的房屋状态是什么)
4) 对关联关系表中实例数据的映射情况进行检验
Q5: SELECT COUNT(takebuilds.Id) FROM takebuilds
JOIN builder ON takebuilds.Company = builder.Company
JOIN builds ON takebuilds.Id = builds.Id
WHERE builder.Company = '沈阳华凌房地产有限公司';(查询沈阳华凌房地产开发的盘有几个)
对于关系数据库进行Q1~Q5查询,得到的查询结果如表5所示。本文利用Q1~Q5的查询条件对生成的RDF(S)文件进行SPARQL查询。查询得到的统计结果与表中的结果是完全一致的,这就表明在对象关系数据库中存储的实例数据进行映射的过程中没有发生数据的丢失。
本文选取Q1和Q5两个查询条件作为示例进行进一步分析。Q1的查询条件对于builder数据表中包含多少个开发商进行查询,该数据表中包含65个开发商。图8给出了对关系数据库查询builder数据表中部分开发商详细信息的结果。

Figure 8. Partial results obtained from Q1 query on database
图8. 对数据库进行Q1查询得到的部分结果
根据提出的构建规则,builder数据表作为基本实体表会被映射称为builder类,而表中所有的数据会被映射成为builder类的实例及其相应属性。所以对于得到的RDF(S)文件中的数据进行相应查询得到的结果如图9所示,查询语句如下:
SELECT ?p ?o WHERE {
?s rdf:type:builder.
?s :builder_Company ?p.
?s :builder_Town ?o.
}
根据SPARQL查询语句可以得知,图9中的p列表示Company属性的值,o列表示Town属性的值。比较图8与图9中的信息可以发现,数据是一致的,说明builder表中数据被构建成了RDF实例。
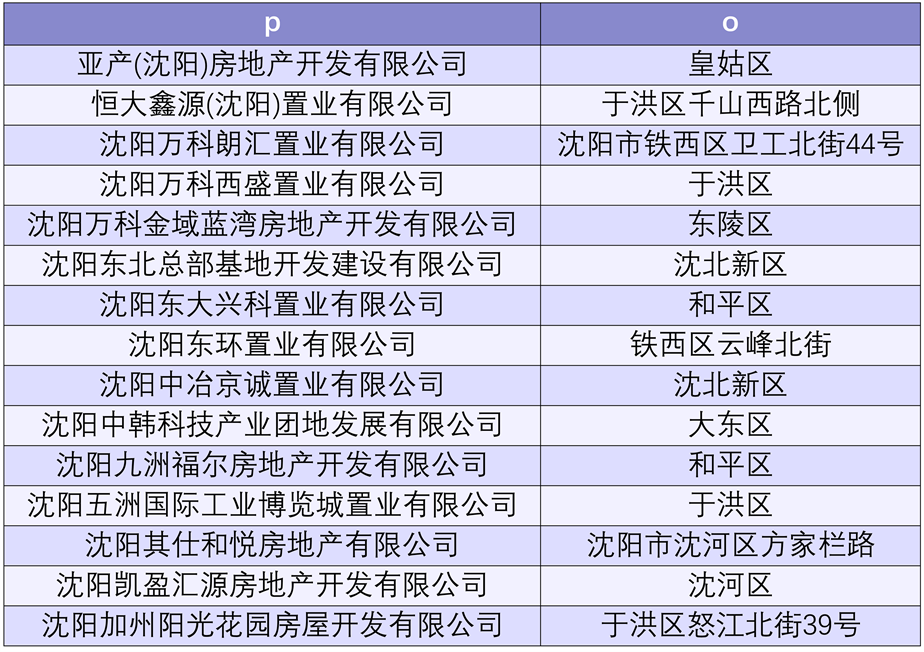
Figure 9. Results obtained by performing Q1 query on RDF file
图9. 对RDF文件进行Q1查询得到的结果
同样对于Q5查询语句得到的结果进行详细分析。Q5 主要对于关联关系表表达的语义信息进行查询,该语句查询得到开发商“沈阳华凌房地产有限公司”开发的项目有2个,图10给出了这两个项目的Id和projectName的详细信息。

Figure 10. Detailed results obtained by performing Q5 query on the database
图10. 对数据库进行Q5查询得到的详细结果
根据提出的构建规则,takebuilds是关联实体表,外键分别引用builds.Id和builder.Company,takebuilds表会被映射成为RDF Schema中属性,所以对于开发商builder.Company为“沈阳华凌房地产有限公司”开发的所有项目进行查询的SPARQL语句如下:
SELECT ?p ?o WHERE {
?s rdf:type:builder.
?s :builder_Company '沈阳华凌房地产有限公司'.
?p :takebuilds ?s.
?p :builds_projectName ?o.
}
该SPARQL语句查询得到的结果如图11所示。

Figure 11. Detailed results obtained by performing Q5 query on RDF file
图11. 对RDF文件进行Q5查询得到的详细结果
通过分析SPARQL语句可知,图11中的p列表示builds类的Id,o列表示该实例的projectName属性。经对比,图10与图11中得到的信息完全相同。这表明映射得到的RDF(S)文件完整保留了关系数据库的语义信息。数据转换的精确性较好。以上内容证明提出的RDB-RDF模式映射的数据转换方法能够实现对象关系数据库的无损转换,传统的方法只能实现的是关系数据库的转换,本文的方法两个层面都能够实现转换。
5. 总结
本文提出了一种基于RDB-RDF模式映射的数据转换方法,转换时首先根据关系数据库和RDF(S)数据的特点,给出二者的形式化定义,将模式层面和实例层面关注点分离开来,分别研究转换方法,使整个转换过程分块进行,更容易理解;同时引入映射描述和连接表达式,使得SPARQL转换为SQL查询的过程变得简单快速,整个方法结合了数据物化和按需映射,不需要转换整个数据库中的数据,只针对SPARQL查询中的部分数据,减少了存储空间。同时本文还对关系数据库进行了扩充,实现了对象关系数据库转换为资源描述框架,这是传统方法不能够做到的内容。实验表明这种方法具备语义完整性,整个过程更加高效。本文的思路还是存在许多的不足,未来的工作方向可以立足于多个关系数据库来实现,设立能够交互的关系数据库,从而实现多个异构数据的融合,进一步满足用户的需要。