1. 引言
1968年麦克斯维尔·麦库姆斯与唐纳德·肖一起提出“议程设置”,该理论在众多学者的实证研究中不断发展,内涵得到了扩充,已成为新闻传播领域中的经典理论。20世纪初期,伴随着媒介的发展,“大众传播威力论”、“子弹论”盛行,直到20世纪40年代,霍夫兰、拉扎斯菲尔德等人通过研究提出“有限效果论”,表示大众媒介的传播效果是有限的。在这一背景下,议程设置理论提出,通过媒介议程和媒体议程的比较,发现媒体的传播效果显著 [1] [2]。现如今,网络媒体盛行、媒介融合不断深化,传统媒体的议程设置效果亟待考察。议程设置理论发展至今,根据显著性考察的不同,可概括三个层次:客体议程设置、属性议程设置和网络议程设置。众多学者通过实证研究检验了“议程设置”理论的存在 [3] [4],但是相关研究的方法较为单一、研究层次不够清晰,数据处理方面缺乏科学性。为了更加严谨客观的论证,本文主要采用机器学习法和社会网络分析法来弥补人的主观影响,并以“中国援助”相关媒体报道和公众讨论的文本为研究对象,来验证“议程设置”的三个层次:1) 公众对某议题的关注程度与他们所接触的媒体对这些议题的关注度是否高度相关?2) 大众媒体是否也影响到公众对议题属性的判断?3) 媒体能否决定公众如何将不同的信息碎片联系起来,构建出对议题的认知网络?于是我们采用相关性分析以及实质性分析来验证第一层次,用机器学习方法来验证第二层次 [5] [6] [7] [8],用社会网络分析方法来验证第三层次,综合以上方法我们更客观的探究了媒介传播效果,验证了“议程设置”的三个层次 [9] [10]。
2. 基本知识
文章中涉及到一些机器学习的算法比较复杂,在本章将给出这些算法的思想,以及算法的基本步骤。
2.1. Word2vec模型
Word2vec模型是托马斯·米科洛夫(Tomas Mikolov)在2013年提出的 [11],作者的目标是从海量的文档中训练得到低维稠密词向量,且词与词之间的语义关联程度可以通过向量的余弦表示。通过Word2vec得到的词向量通常作为其他神经网络的输入应用在一些自然语言处理的任务中。本文将用Word2vec模型对媒体报道和公众评论的文字进行数值向量化。
2.2. 支持向量机
支持向量机(Support Vector Machine)是Cortes和Vapnik于1995年提出的 [12],它在解决小样本、非线性及高维模式识别中表现出许多特有的优势,并能够推广应用到函数拟合等其他机器学习问题中,使得SVM适用分类范围越来越广 [13] [14]。SVM,从线性可分模型到非线性可分的软边界模型,再从低维线性不可分映射到高维线性可分的核函数思想等过程组成。本文将用SVM对媒体报道和公众评论进行分类分析。
2.3. TextRank算法
TextRank算法是一种用于文本的基于图的排序算法 [15]。其基本思想来源于谷歌的PageRank算法,PageRank设计之初是用于Google的网页排名的,以该公司创办人拉里·佩奇(Larry Page)之姓来命名,它可以用来体现网页的相关性和重要性。在利用TextRank算法选出文章的关键词时,最终会得到一系列关键词及其对应的权重。本文将用TextRank算法选出媒体报道和公众评论的关键词并得到相应的权重等。
2.4. 网络可视化及相似度检验
2.4.1. NetDraw可视化
为了更直观体现在“中国援助”这个议题每个属性之间的联系,本文使用NetDraw工具可视化媒体和公众的网状图。该工具由美国肯塔基州立大学Gatton商学与经济学院管理系Steve Borgatti教授开发,目前已被广泛应用于社会网络分析研究 [16] [17]。
本文,在同一篇报道或同一公众评论中任意两个词语出现,我们称这两个属性共现,并认定为这两个属性之间存在关联。NetDraw网状图是由节点和连线组成,用节点大小表示属性的重要性,节点越大表示该词出现的越多,在网络中越重要,用连接线表示两个属性的共线,用线的粗细来直观表现属性之间的关联程度。
2.4.2. QAP相关性分析
社会网络分析中,另有一种方法用来研究两个方阵的相关性,这种方法是QAP二次指派程序 [18]。QAP的计算原理是以矩阵置换为基础,其针对两个n维的对称矩阵A和B的QAP计算过程见文献 [18],我们将用该方法分析媒体属性矩阵和公众属性矩阵之间的相关性,从而分析媒体报道对于公众的影响。
3. 议程设置验证
本节将通过简单相关分析、SVM模型、社会网络分析方法验证议程设置的三个层次,并给出实验中数据处理的具体步骤。
3.1. 实验准备
3.1.1. Word2vec模型训练
本文基于Word2vec模型将文本向量转换为词向量,在转换之前需要先训练Word2vec模型。该模型的训练数据,是在搜狗实验室下载的1.5G的全网新闻报道,训练由Spyder平台完成,Python版本为3.7。
3.1.2. 第一层次验证的数据收集
在慧科数据库,以“中国援助”为关键词,搜索条件设置为包含“中国援助国外”、“中国物资”、“中国专家”和“中国口罩”这些词中任意一个,时间段设置为2020年3月1日至2020年4月30日,数据库显示这段时间内关于“中国援助”的新闻报道共31,293篇。其中每一天的新闻报道篇数依次是:9、22、18、34、66、44、98、25、62、91、97、121、345、680、1105、1251、463、648、252、370、255、1331、1597、785、964、1570、1283、1065、1134、857、600、564、589、490、215、308、1532、1582、600、743、525、525、136、331、254、125、、404、170、222、777、797、287、482、196、154、67、84、266、416、576、634。
百度作为全球最大的中文搜索引擎,以其快捷方便特点满足了中国国内民众的搜索习惯。百度指数(Baidu Index)是以百度海量网民的行为数据为基础的数据分析平台,某个关键词在百度平台的搜索规模大小,都会体现在百度指数的涨跌态势上,所以百度指数一段时间内的涨跌态势可以反映国内民众对这个舆论的重视程度的变化。为了通过大数据体现民众对中国援助的话题的关注度,本次研究选用了百度指数作为平台。
在百度指数,以“中国援助”为关键词,统计了2020年3月1日到2020年4月30日,有关“中国援助”的百度指数走势,61天每天的指数数据依次为:173、218、198、174、207、176、225、296、319、354、426、591、1316、1220、1285、1679、2004、1450、1601、1471、1247、1523、1426、1212、1287、1589、1450、1268、1199、1067、1015、834、687、708、1101、614、510、441、426、385、395、399、338、326、324、370、364、339、332、336、285、238、234、294、255、315、295、261、229。
3.1.3. 第二三层次验证的数据搜集和处理
在第二层次和第三层次的证明中,若使用2020年3月1日至2020年4月30日这段时间内关于“中国援助”的所有数据,则不仅增加研究样本的噪声,而且在训练网络时浪费大量资源。故本次研究从中分别抽取300篇媒体报道和公众评论做分析。为了让数据具有代表性,需要保证每天都能抽到数据,下面设每天要抽取
篇,则
计算公式如下:
当
时,
取1;当
时,四舍五入取整数。这段时间内媒体报道的总篇数为31,293篇,比如第1天报道篇数为9篇,则第1天抽取的篇数
为
,那么第1天就在9篇里随机抽取1篇;再如第16天报道篇数为1251篇,则第16天抽取的篇数
为
,那么第16天在就应当在1251篇里随机抽取为12篇。随机抽选是用计算机先在区间(0,当天报道篇数)内生成
个随机数,再根据这
个随机数在当天的总篇数里挑选出对应的篇数。
抽取后的数据在输入SVM模型之前,还需要进行一系列处理,下面以媒体数据为例。
①标签设置:先把300篇新闻报道分成正面报道和负面报道,以数字“1”为正向标签,数字“0”为负向标签,300篇媒体报道中有238篇正面报道,62篇负面报道(公众有194篇正面评论,106篇负面评论)。
②文本清洗:把300篇文章整合到一个文件,去除如空格、数字和字母等各种无用的符号。
③结巴分词:jieba库是一款优秀的Python第三方中文分词库,多应用于自然语言处理领域,它可以将中文句子分解成词语。如“据央视新闻报道,国内新冠肺炎现有确诊病例降至10,000以下了!”这句话分词后的结果为“据央视新闻报道国内新冠肺炎现有确诊病例降至以下了”。
④去停词处理:这项工作是为了降低数据噪声,避免把没有实际意义的词输入模型训练。本文选定中科院计算所中文自然语言处理开放平台发布的中文停用词表,其中包含了1208个停用词,结合本次实验的数据特征,在原有词典的基础上,添加了如“来源、人民日报、新华社、慧科讯业有限公司、文章”等20多个适用于新闻数据的特殊停词,增强了去停词的效果。
⑤文本向量化:中文文本是不能直接输入到模型的,需要用到Word2vec工具把中文文本转化为词向量形式。公众评论数据的处理与上面媒体数据的处理步骤类似。
3.2. 第一层次验证
3.2.1. 相关性分析
议程设置第一层次考察的是客体显著性的转移,可以理解为公众对话题的讨论趋势与媒体的趋势具有一致性,在数据上的表现就是在一段时间内,公众对某个议题的讨论的量应该与媒体对该话题报道的量成正比。
通过计算两组数据的相关性,发现相关系数达到0.561,呈强相关。在2020年3月1日至2020年4月30日期间,民众对“中国援助”话题的关注度如下图1所示。
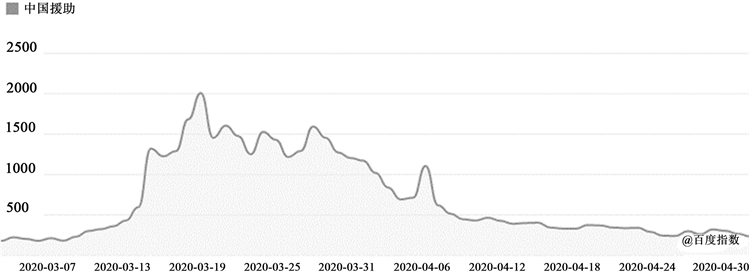
Figure 1. Public attention trend to “China assistance”
图1. 民众对“中国援助”的关注趋势
由图1可知,公众对中国援助的讨论在3月1日到3月9日处于缓慢上升阶段(试探期),3月10号到3月13号呈现快速拉升趋势(升级期),3月14日到3月30日讨论热度居高不下(激化期),4月1日到4月30日热度下降回到平缓趋势(消退期),其中公众讨论的高峰期出现在3月14日到30日期间,与媒体报道量对比,发现二者的趋势具有一致性。
媒体通过对“中国援助”这一议题的大量报道,引发了公众对该议题的大量讨论,第一层次议程设置效果显著。
3.2.2. 时滞期分析
在议程设置的研究中,时滞期一直是一个研究要点,时滞期是指议程的一方影响另一方需要的时间 [19]。Roberts等人研究表明:传统媒体影响公众讨论的时滞期应该相对较短,传统媒体的新闻报道影响EBB上的网络讨论所需的时间为1到7天,并且当时间滞后为7天时,媒介议题与公众讨论议题的相关性最强 [20]。利用上面的两组数据,本文对当代媒体的时滞期进行了有趣的研究。发现当把两组数据错开几天时,也就是把当天的新闻报道量,与过几天的百度指数相对应,相关系数变化结果如下表:

Table 1. Correlation coefficients between media coverage and Baidu Index
表1. 媒体报道量与百度指数的相关系数
由上表1可以看出,随着两组数据错开天数的增加,相关系数直线下降,到错开7天时,两组数据变得完全不相关,当错开天数为0天时,即当天的媒体报道量对应当天的公众讨论,两组数据的相关性最强。
互联网使得万物互联、万物互通。在改变人们生活方式的同时,也极大的改变了传播的方式,给传统媒体的时效性带来了极大的挑战。通过相关性的比较发现,在当代媒介环境下,议程设置的最佳时滞期在变短,已经从7天缩短到了当天,媒体对公众的影响愈加及时。
3.3. 第二层次验证
本节将通过SVM模型验证议程设置的第二层次。首先在2020年3月1日至2020年4月30日这段时间按比例选出300篇新闻报道和300篇公众评论,作为测试数据,再将数据经过一系列的预处理、降维,最后将数据输入到SVM模型进行分类,并根据分类结果分析媒体和公众的情感倾向。
3.3.1. SVM模型训练
SVM是一个有监督学习的分类器,相当于一个人类的大脑,想要达到自主分类的功能,必须先训练“大脑”。训练数据是人工标记的,来自于慧科数据库的媒体报道数据,其中包含了正面和负面的评论各300条,输入SVM模型进行训练,并把训练好的模型保存好,在接下来的分类中使用。
3.3.2. 基于PCA降维的数据优化
新闻数据有两个特性,一是新闻报道篇幅过长且包含很多无用的信息,二是一篇报道里面会出现既褒又贬的观点,如赞成对一些国家援助的同时又反对对部分国家提供援助。考虑到这些因素,本文对数据使用了PCA (Principal Component Analysis)降维技术,PCA可以将词向量矩阵里线性相关的项去掉,保留线性无关的特征,从而降低了数据维度,达到去噪的效果 [21]。将数据进行PCA降维结果如图2、图3所示。
由上图2和图3可以看出,媒体报道数据中,前50维数据对整个数据几乎作了全部贡献,即可以使用前50维数据来替代所有数据去进行分类,而公众评论数据中,前20维数据几乎作了全部贡献。因此,在SVM分类时,媒体数据选取前50维,公众数据选取20维。
3.3.3. SVM分类
在机器学习领域,评价模型分类结果的好坏,常用到ROC (receiver operating characteristic curve)曲线。ROC曲线位于平面坐标系中,其中横轴X轴为假阳性率,也称为误报率,X轴越接近0准确率越高;其中的纵轴Y轴称为真阳性率,也称为敏感度,Y轴则越接近1代表准确率越好(Hanley和Mcneil,1982)。
如图4和图5所示,虚线把整个图划成了两部分,曲线下方的面积称AUC (Area Under Curve),用来比较预测的准确性,AUC值越高,则曲线下方面积越大,就说明预测准确率越高,图4的AUC值为0.903、图5的AUC值为0.888。

Figure 2. PCA dimensionality reduction results of media coverage data
图2. 媒体报道数据PCA降维结果

Figure 3. PCA dimensionality reduction results of public comment data
图3. 公众评论数据PCA降维结果
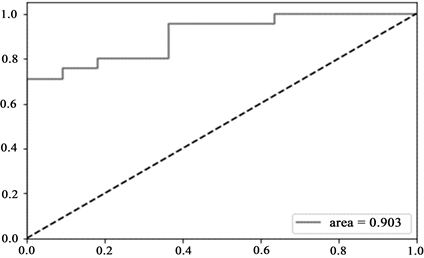
Figure 4. ROC curve of SVM classification in media coverage
图4. 媒体报道的SVM分类的ROC曲线
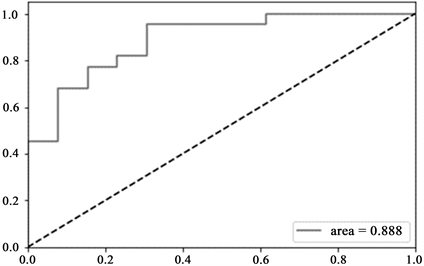
Figure 5. ROC curve of SVM classification of public comments
图5. 公众评论的SVM分类的ROC曲线
3.3.4. 分类结果分析
经过PCA数据降维后,得到了媒体报道和公众评论的分类正确率如下表2。
随机抽取的300篇新闻报道中,有238篇正面报道,62篇负面报道,在SVM模型正确率为87.5%情况下,SVM结果认为媒体对新冠肺炎下关于“中国援助”的报道是偏向积极的。随机抽取的300篇公众评论中,有194篇正面评论,106篇负面评论,在正确率为82.9%的情况下,SVM结果认为公众对新冠肺炎下关于“中国援助”的态度也是积极的。因此,在“中国援助”这个议题上,媒体的态度与公众的态度是一致的,媒体不仅影响了公众讨论什么,还影响了公众看待“中国援助”的态度,属性发生了转移,议程设置第二层次得到了验证。
Table 2. Classification and prediction results of media coverage and public comments
表2. 媒体报道与公众评论分类预测结果
3.4. 第三层次验证
本节是通过TextRank算法和社会网络分析方法验证议程设置的第三层次。首先会用TextRank算法选取出媒体报道和公众评论的15个属性词,再构建属性矩阵,进而通过NetDraw进行可视化,最后通过QAP分析两个属性矩阵的相关性,根据相关系数判定媒体网络对公众网络的影响。
3.4.1. 基于TextRank算法选取属性词
第三层次的关键是在媒体报道和公众评论这600篇文章中概括出属性词。之前的研究在筛选属性词过程中大多加入了主观情绪 [22],本文为了使选出来的属性词更客观也更具有代表性,使用了自然语言处理领域常用的提取关键词工具TextRank算法,它能够从一个给定的文本中提取出该文本的关键词、关键词组 [15],TextRank算法会计算每个词的重要性。表3和表4是基于TextRank算法抽取的重要性靠前的关键词表格。
依据TextRank算法选取的重要度程度靠前的关键词,去除一些无意义词和同义词(国家、没有、世界……),最终选定了贡献度最高15个属性词:中国、意大利、美国、口罩、援助、物资、病毒、武汉、欧盟、俄罗斯、特朗普、人道主义、医疗队、巴基斯坦、武契奇。
Table 3. Importance of key words in media
表3. 媒体关键用词重要性程度
Table 4. Importance of key words in public
表4. 公众关键用词重要性程度
3.4.2. 构建属性矩阵
新闻报道或公众评论中相关属性的共现次数被计算出来用以测量任意两个属性间的关联强度。两个属性词在同一篇报道或同一个公众评论中共同出现的频率越高,这两个属性之间的关联就越强 [11]。本文分别统计出媒体报道和公众评论中属性词的共现次数,共统计600次,获得媒体和公众的共现矩阵。
从表5和表6可以看出,属性矩阵是对称矩阵,对角线上是无意义数据,其他表格中的数据表示两个属性词在同一篇文章中同时出现的次数,如在媒体矩阵中,中国和意大利对应的表格显示为2734,这表示在媒体矩阵的300篇文章中,中国和意大利同时出现在某一篇文章的次数和2734。
3.4.3. 网络可视化
将属性矩阵通过excel表导入NetDraw,得到媒体属性矩阵如下图6所示。
本文通过网络可视化来分析新冠疫情下中国援助的媒体议程和公众议程各属性之间的联系。通过NetDraw对媒体矩阵进行可视化,得到了媒体议程网络。通过UCINET软件进行点度中心性分析发现,媒体议程网络各属性词根据数值排序依次为:中国(点度中心度13,684)、援助(点度中心度10,041)、物资(点度中心度9672)、意大利(点度中心度8926)、口罩(点度中心度7407)、病毒(点度中心度5488)、美国(点度中心度5388)、病毒(点度中心度5488)、欧盟(点度中心度2258)、巴基斯坦(点度中心度2137)武汉(点度中心度2028)、医疗队(点度中心度1938)、武契奇(点度中心度1811)、特朗普(点度中心度1196)、俄罗斯(点度中心度1108)、人道主义(点度中心度865),其中度是与一个节点相关联的边的条数,有向图中每个节点都有一个出度和入度,分别是指入边和出边的条数,度被指为结点的“关联性”。
在议程网络中,不同的属性词由不同大小的蓝色方块组成,方块的大小代表了每个属性的点度中心度,点度中心度表示与该点直接相连的点的个数。节点的点度中心度越大,就意味着这个节点的度中心性越高,该节点在网络中就越重要。因此,在媒体议程中中国、援助、物资等是强调的重点内容。度中心性越高,与网络的其他属性联系就更多,连接线的粗细可以代表关系紧密程度,线越粗联系越紧密。在媒体议程设置中,中国与意大利、口罩、物资、援助、美国之间有着紧密的联系。
同样,将公众矩阵输入到NetDraw,得到公众矩阵如图7所示。
在NetDraw显示的图像中,每一个节点都代表一个属性,本研究以中心度结果显示节点的大小,节点越大表明它的度中心性越高,与其他节点联系更紧密,在网络中也越处于重要的位置。公众议程中,各属性次根据点度中心度数值排序依次为:中国(点度中心度1573)、援助(点度中心度1220)、物资(点度中心度719)、美国(点度中心度660)、意大利(点度中心度436)、口罩(点度中心度397)、病毒(点度中心度346)、欧盟(点度中心度157)、医疗队(点度中心度154)、俄罗斯(点度中心度108)、人道主义(点度中心度104)、武汉(点度中心度102)、特朗普(点度中心度78)、武契奇(点度中心度64)、巴基斯坦(点度中心度60)。
与媒体议程相同,公众也对中国、援助、物资、美国、意大利、口罩、病毒、欧盟给予了重点关注。同时在公众的脑海中,中国与物资、美国、援助之间存在着紧密联系。值得注意的是,根据点度中性的数值和排序发现,与媒体议程更关注“意大利”相比,公众对“美国”的关注度最高,并对巴基斯坦的关注度最低。
3.4.4. 基于QAP的相关性分析
QAP分析(Quadratic Assignment Procedure)程序可以对媒体共现矩和议程共现矩进行相关性分析和回归分析,两个矩阵相关系数越大,证明矩阵间的相关性越大。通过数据显现,媒体矩阵与公众矩阵的相关系数达到了0.831,媒体议程与公众议程正向显著相关,媒体第三层次议程设置效果显著。议程网络实现了将公众脑海中的具体景象描绘了出来,为媒体在新媒介下改善议程设置,发现公众议程的关注重点和思维逻辑提供了重要参考依据。在“中国援助”这一事件中,媒体不仅影响公众“想什么”和“怎么想”,也成功影响了公众的认知网络。
4. 结论
本文基于机器学习算法和网络分析方法,研究了在新冠肺炎环境下“中国援助”的议题,客观的检验了议程设置的三个层次。与之前的学者不同,本文在第一层次的研究中,通过把媒体数据和公众数据错开天数作分析,得出到在当代媒介环境下,议程设置的最佳时滞期从7天缩短到了当天,媒体可以及时影响公众;在第二层次的研究中,本文不再依据阅读媒体文章和公众评论自主归纳出媒体和公众态度,而是通过数据训练一个神经网络“大脑”,让机器的“大脑”去判断,极大提高了研究的客观性,结果更让人信服;在验证议程设置的第三层次时,属性词的选取一直是之前研究的难点,不论是通过研究者自己归纳还是依据问卷让公众提供,都存在较大误差,本文使用的TextRank算法结合上下文,选出文章中贡献度高的词语,为选取属性词提供了新思路,并让第三层次得到了客观和合理的验证。
通过本文的分析,还发现,在新媒介环境下,媒体可以通过以下路径进一步优化“中国援助”的议程设置。1)媒体需进一步弘扬人道主义缓解公众消极情绪;2)媒体应进一步提升国际影响力,改善国际舆论场;3)媒体可加强细节报道引发公众关注。
基金项目
北京工商大学教育教学改革研究项目(jg215203)。
NOTES
#万鑫、唐润发同为第一作者。