1. 引言
目标识别检测技术是计算机视觉的重要分支,广泛应用于工业、军事,尤其是无人驾驶领域。在车辆、行人、交通标识等标志物的识别里发挥了重要作用。传统的目标检测算法大多使用可见光进行目标检测,在夜间、沙尘暴、雾雨天气等可见光资源较少、目标距离较远的情况下,很难进行有效的成像,检测效果欠佳,而红外影像技术基于检测物体的红外辐射能量进行成像,在无光的夜晚或者烟尘环境里依旧可以成像,受可见度低等因素影响较小,因而被广泛应用于夜间成像与非接触测温应用等多个领域。
传统的目标检测算法通常采用滑动窗口的方式,即采用一个窗口,在检测图片上滑动选取感兴趣区域,分别对滑动的每个窗口进行特征提取,如方向梯直方图(Histogram of Oriented Gradients, HOG) [1]、局部二值模式(Local Binary Pattern, LBP) [2]、尺度不变特征变换(Scale-Invariant Feature Transform, SIFT) [3] 等,之后对提取的特征利用机器学习算法。但是由于不同图片的尺寸存在差异,如果使用固定窗口选取会存在重复、遗漏等问题,并且如果采用不同滑窗方式识别会出现计算量大,速度过慢的问题。
传统的红外影像目标检测方法一般有背景差分法、帧间差分法、光流法。Wren等人 [4] 将图像中当前帧与已经确定或实时获取的背景图像作差,从而获得物体的位置大小等相关特征。Yin等人 [5] 提出可以将相邻的几帧图像进行相减,并且对作差后的图像镜像阈值化来获得物体特征。Horn和Schunck等人 [6] 利用图像上像素在时间上的变化及其相关性来计算物体运动状态。
近些年来,随着卷积网络的出现,自动提取特征,更高的准确率,更快的运算速度等特点使得基于深度学习的目标检测方法得到广泛研究。目前,基于深度学习的目标检测算法主要分为两类:二阶段(Two stage)目标区域检测算法和一阶段(One stage)目标区域提取算法。基于区域检测的目标检测算法先进行区域生成,该区域称之为region proposal (简称RP,一个有可能包含待检物体的预选框) [7],再通过卷积神经网络进行样本分类。常见two stage算法有:R-CNN [7]、SPP-Net [8]、Fast R-CNN [9]、Faster R-CNN [10] 和R-FCN [11]。基于区域提取的目标检测算法则是不用RP,直接在网络中提取特征来预测物体分类和位置。常见的one stage目标检测算法有:OverFeat [12]、YOLOv1 [13]、YOLOv2 [14]、YOLOv3 [15]、SSD [16] 和RetinaNet [17] 等。
YOLO算法相较于R-CNN系列算法,仅通过一个卷积网络就能实现对目标物体的位置与类别的检测,凭借其实时性高、便于操作的特点得到了广泛应用。而YOLOv3作为YOLO系列的巅峰之作,不但延续了YOLO系列的便捷性,更是做出了改进。首先在特征提取部分采用darknet-53的backbone代替之前的darknet-19,实现多尺度特征融合,在保证了实用性的同时,又提高了准确性。而在无人驾驶领域对于车辆和行人的目标检测,YOLOv3的灵活性满足了笔者对于目标检测的需要,同时针对于目标检测算法在夜间环境下的检测精度较低的问题,采用Flir红外影像数据集,利用红外影像夜间成像的优势,对于YOLOv3的backbone、特征融合与损失函数三方面进行微调改进,实现对于夜间车辆与行人的目标检测。
2. 改进的YOLOv3目标检测算法
2.1. YOLOv3基本原理
YOLOv3是一阶段(One stage)的目标检测算法,将输入图像划分成三种不同网格,分别对应目标检测的小尺寸目标,中尺寸目标,大尺寸目标。YOLOv3的backbone采用DarkNet-53 [15] 的残差神经网络,能够在加深网络的同时又较好地解决梯度消失的问题,有助于数据训练和特征提取融合。YOLOv3的网格结构如图1所示。在多尺度特征融合方面,YOLOv3采用FPN (feature pyramid networks) [18] 特征融合结构。
2.2. 深度可分离卷积
2017年Howard [20] 等人提出了深度可分离卷积(depthwise separable convolutions),通过分步卷积方法大幅降低了模型的参数量。因此为了防止模型参数量过大的问题,本方法将后三个常规卷积更换为深度可分离卷积。深度可分离卷积主要分为两个过程,分别为逐通道卷积DW (Depthwise Convolution)和逐点卷积PW (Pointwise Convolution)。首先,图像输入经过第一次卷积运算,逐通道卷积的一个卷积核负责一个通道,卷积核的数量与上层的通道数一致,计算量为卷积核W × 卷积核H × (图片W − 卷积核W + 1) × (图片H − 卷积核H + 1) × 输入通道数。但逐通道卷积生成的Feature map数量与输入层的通道数相同,没有有效利用不同通道在相同空间位置上的Feature信息,因此需要后续逐点卷积对于生成的Feature map进行组合。逐点卷积部分则是进行1 × 1卷积,进行单点上的特征提取,将上一步生成的Feature map在深度方向上进行加权组合,生成新的Feature map。其计算量为特征层W×特征层H×输入通道数 ×输出通道数。
将后续常规卷积更换为深度可分离卷积的方法,相较于常规卷积而言,在保证精度不会损失太多的情况下,大大降低了计算量与参数量。同时深度可分离卷积经常规卷积同时考虑区域和通道的拆分,深度可分离卷积先只考虑区域,然后再考虑通道。实现通道和区域的分离。
2.3. 模型改进
基于上述问题,文中针对于YOLOv3的backbone、特征融合和损失函数三个部分进行优化改进,优化主干网络,增加大尺寸图像的卷积次数,提高特征提取能力。同时将部分普通卷积更换为深度可分离卷积,降低参数量。特征融合部分将FPN更换为PANet [19] 中的结构。在损失函数方面将archor中的定位误差改为CIoU [21],减少损失程度,增强信息丰富度。
2.3.1. Backbone
YOLOv3的backbone采用的是由残差网络(Residual)组成的Darknet-53,在加深网络的同时又能较好地解决梯度消失问题。本文为减少图像在卷积过程中损失过多信息,将前两个残差单元的卷积次数分别从1,2增至2,4,提高大尺寸图像的特征提取能力,改进后的残差网络进行特征提取流程图如图3。其中每个残差单元首尾连接,组成一个大残差边,这样较为有效地减少了传统卷积层在特征提取的过程中存在的信息丢失、损耗的问题,有效地保护了信息的完整性,以两个小残差单元为例,改进的残差单元结构如图2所示。
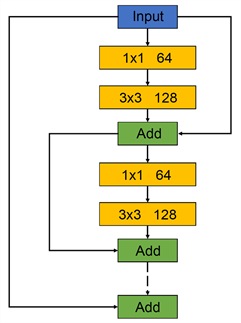
Figure 2. Improved residual unit structure diagram
图2. 改进残差单元结构图
为了保证添加上述残差单元的模型参数量不至于过高,本文将后三个残差单元中的常规卷积更换为深度可分离卷积,较好地减少了参数量并提高了模型运行速度。改进后的残差网络特征提取流程如图3。

Figure 3. Improved residual network feature extraction flowchart
图3. 改进后残差网络特征提取流程
2.3.2. 特征融合
YOLOv3的特征融合结构采用自下而上融合方式,由上层小尺寸特征图经上采样与下层大尺寸特征图融合,然后将融合后的三个尺寸特征图分别检测。而本文采用的是对比度较低的红外影像数据,相比于RGB格式的彩色图像,特征提取更加苦难。所以为了增加网络对提取特征的有效利用,将YOLOv3中的特征融合结构更换为PANet中的结构。PANet结构在FPN的基础上又增加了一个从低层特征层到高层特征层的路径,将低层特征语义信息二次向上层传递,增加了底层特征语义信息的传递率与利用率,结构如图4所示。
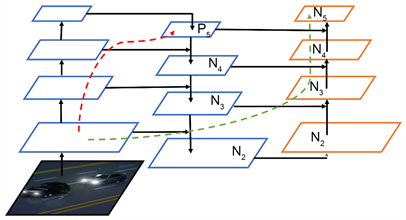
Figure 4. Improved feature fusion structure diagram
图4. 改进特征融合结构图
2.3.3. 损失函数优化
YOLOv3的损失函数由检测物体中心点的坐标误差(x, y),anchor box的宽高坐标误差(w, h),置信度误差(confidence),分类误差(class)组成。具体函数表示如下:
为预测框中心坐标误差,其中
是YOLOv3的预测框中心点坐标,
为设定预测框的中心点坐标,
为预测框
是否检测一个目标物体,其值为1或0。
为预测框宽高误差,其中
为预测框宽高,
为
设定预测框的宽高。
为预测框置信度损失,
为预测框中是否含有目标检测物体的概率,
为其真实值。
为预测框中目标物体的类别损失,
表示预测框中目标检测物体是否属于检测类别的概率,
其所属类别的真实值。
在实际训练中anchor坐标回归对模型收敛其到至关重要的作用,所以一个合理的损失函数可以加快模型收敛。所以本文将YOLOv3的anchor损失函数替换为DIoU (Distance-IoU) [22],DIoU计算公式为:
3. 实验结果分析与讨论
为了验证本文提出算法的有效性,选择由Flir公司发布的开源红外数据集进行对比实验。Flir数据集于2018年7月发行,数据集包括同步注释热图像和无注释RPG图像供参考,共有14,000张图像,以30帧频率记录视频信息。注释标签包括行人、汽车、自行车、狗等标签。考虑到训练样本的平衡性,本文选取目标数量最多的汽车和行人构建训练数据集,共7000张。为了保证实验的公平性,本文采用完全相同的超参数对YOLOv3和改进模型分别进行训练,采用AP和mAP作为评价指标,对比结果如表1所示。
由表1可以看出本文改进算法在模型大小几乎不变的情况下,相比于YOLOv3在行人和汽车两类上分别有2.94%和3.12%提升,平均AP也有3.03%的提升。为了更直观的展现改进算法识别能力,选取了非训练集的红外影像6张进行实际识别,识别结果如图5所示。

Table 1. Comparative experimental results
表1. 对比实验结果
从图5可以看出,改进的模型针对于不同道路情况,覆盖行人和机动车数量不同的各种情况,均实现了较好的识别效果,在识别率和召回率方面均有不错的表现,远处小目标没有出现漏检情况,人车密集的场所也能做到全部准确识别分类。
4. 结论
针对于夜间自动驾驶常规目标检测行人与车辆效果不佳的问题,本文提出一种基于YOLOv3算法的红外影像目标检测。该方法基于YOLOv3算法,优化调整其backbone结构,增加大尺寸图像的卷积次数,提高特征提取能力,并将后续常规卷积更换为深度可分离卷积,以减小模型参数量,加快模型运算速度。并将YOLOv3算法多尺度融合中的FPN模型更换为PAnet模型,加快底层语义信息的传递效率。同时在损失函数部分采用DIoU结构,加快模型收敛。并通过在Flir红外影像集上的测试,本文所提出的算法在模型量基本不变的情况下,相较于原始YOLOv3技术有较明显提升,对于行人和机动车检测率都有不错表现,平均AP提高了3.06%。本文下一步工作将注重于夜间自动驾驶更多交通标志物的检测,同时进一步优化改进模型,提高目标检测效率的同时减少模型参数量。