1. 背景
目前,全国大部分省(区、直辖市)正开展降水天气现象平行观测工作,但是从目前全国统计的数据分析发现,目前安装的降水现象仪对于常见的雨、雪降水现象,可以捕获到降水过程,平均捕获率为70%,但是错报、漏报率较高;对于雨夹雪、冰雹这些不常见的天气现象,捕获率较低,漏报率较高。现需要统计全国2242个台站近几年的真实观测数据,得到符合各台观测特性的降水类型识别方法。
目前降水现象仪不能满足用户需要,根本原因在于目前各厂家降水类型识别算法均是依靠国外试验所得经验公式,按照32等级粒径和32等级粒速粒子分布情况,绘制降水类型识别图 [1] [2]。在此图中虽然雨区、雪区及冰雹区在尾端有明显的分界线,而在前端则重叠区域较多;毛毛雨包含在雨区前端,雨夹雪区则为雨区和雪区内的中间部分组成 [3]。这种方法,只利用了区域位置信息和简单的粒子数量分级,并且我国疆域辽阔,地域性强,该方法通用性不强,不能准确分辨天气现象。
本文采用基于深度学习的图像分类方法 [4],首先解析雨滴谱文件,生成包含粒径、粒速和粒子数量信息的二维图像;再利用人工观测天气现象对生成的二维图像进行人工标注,形成数据集;最后利用深度学习图像分类方法搭建降水现象自动识别模型。
2. 降水现象识别方法
雨滴谱传感器由激光发射装置、激光接收装置、温控装置、处理单元等部分组成,通过检测通过采样区的降水粒子的尺寸和速度,获取雨滴谱信息,区分降水类型 [5] [6] [7]。二维图像具有颜色特征、纹理特征、形状特征和空间关系特征。本文把雨滴谱传感器生成的报文按照32等级粒径和32等级粒速粒子分布的数量,生成二维图像,一方面获取了区域位置信息,另一方面把粒子数量信息转换成像素值,获取了颜色特征、纹理特征和形状特征。
考虑到目前基于卷积神经网络的深度学习方法在图像处理领域表现出来的优势及其对特征刻画的优秀表现,我们的目光就聚焦到了卷积神经网络上,卷积网络通过自动学习训练数据中的特征,对特征自动进行抽取和筛选,从而得到理想的特征提取模型,相比于人工提取特征,卷积神经网络排除了人的主观因素 [8],使特征提取更加准确和合理。
本文基于深度学习的降水现象自动识别方法,首先收集雨滴谱传感器生成的报文,生成二维图像并制作成图像分类模型所需的数据集;接着根据降水现象分类需求,搭建神经网络,进行模型训练,生成自动识别模型;最后对模型进行测试,检验模型的可用性。
3. 数据集制作
雨滴谱文件中存储了每日每分钟累计粒子数量。解析雨滴谱文件,每日每分钟生成一幅雨滴图,每日1440张图片,其中当前分钟无天气现象的图片删除,每日最多产生1440张,最少0张。A文件中存储了每日天气现象人工观测结果,精确到分。依据A文件中人工观察结果把雨滴图分类到对应的天气现象类别中。
对50772、50892等23个站提供的雨滴谱文件和A文件进行解析,生成数据集,数据集收集到包含五种天气现象图片435,698张,其中毛毛雨9867张、雨337,595张、雨夹雪9134张、雪79,100张、冰雹2张,详情如表1台站数据汇总表所示。

Table 1. Summary table of station data
表1. 台站数据汇总表
虽然样本种类涵盖了全部五种天气现象,但是每一种类样本数量差异较大,雨、雪图片数量多,冰雹图片只有2张,毛毛雨和雨夹雪有1万张左右,且毛毛雨现象只在3个台站出现,样本分布呈现明显的不均衡。挑选了部分具有代表性的二维图像进行分析,详情如下图1五种天气现象二维图所示。从二维图中可以看出,不同的天气现象呈现的二维图像有明显的差异,这为本文采用图像分类方法识别天气现象奠定了基础。

Figure 1. Two-dimensional map of five weather phenomena
图1. 五种天气现象二维图
基于样本均衡性的考虑,把23个站数据合并在一起组成一个包含4类天气现象的数据集,其中毛毛雨9867张、雨10,000张、雨夹雪9134张、雪11,300张,详情如表2训练数据集所示。
4. 模型搭建与训练
通过分析数据集规模,按照5:1的比例划分训练集和验证集,把数据集中每个样本当作分辨率为(32, 32)

Figure 2. The structure diagram of the five types of precipitation recognition depth model
图2. 五种降水类型识别深度模型结构图
的图像,利用图像分类的方法,针对雨滴谱样本搭建了一个包含20层,15,896,132个参数的深度网络 [9],上图2五种降水类型识别深度模型结构图展示了该网络的结构。该网络输入尺寸(32, 32, 3),经过多次卷积、池化,最后通过全连接层变形、压缩,输出一个(5, 1)的数组。
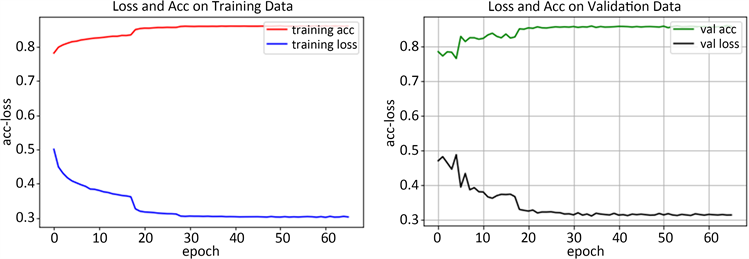
利用搭建的五种降水类型识别深度模型,在四万张样本的数据集上展开训练。本实验采用的仿真平台为64位window7操作系统,硬件环境为内存16 G,Intel (R) Xeon (R) E5-1607,GPU NVIDIA Quadro K600。选用的深度学习开源框架为Tensorflow,调用GPU实现卷积神经网络的并行运算。模型设置训练epoch = 100,batch_size = 32,初始学习率采用默认值,经过52小时的迭代学习,模型训练准确率和验证准确率不再变化,趋于稳定。下图3展示了训练集数据识别的准确率和验证集数据识别的准确率,随着训练次数增多,训练平均准确率和验证平均准确率不断上升,最后稳定在86%附近。
 (a) (b)
(a) (b)
Figure 3. (a) Recognition accuracy rate of training set; (b) Verification set recognition accuracy
图3. (a) 训练集识别准确率;(b) 验证集识别准确率
5. 结果及分析
基于样本均衡的考虑,训练时只用了雨、雪的部分样本,我们把剩余样本作为测试集,其中雨的测试样本320,446张,雪的测试样本67,800张,详细情况如表3测试数据集所示。利用训练好的最优模型,对两类测试数据进行测试,验证下模型的泛化能力。
5.1. 雨样本测试
雨的测试样本320,446张,利用训练的最优模型对雨样测试集进行自动识别,识别结果毛毛雨86,682张,占总数26.4%;雨198,350张,占总数62.7%;雨夹雪30,226张,占总数9.2%;雪5188张,占总数1.5%,详情情况如表4雨测试准确率统计表所示。
雨的识别准确率是62.7%,其中错报率较高的是毛毛雨,达到26.4%。雨和毛毛雨的总识别率达到89.1%,说明雨和毛毛雨的样本相似度高,与雨夹雪和雪区分度高。经过分析发现,同一时段人工观测有时候会多个现象同时出现,这个问题直接导致雨的错报率提高。下一步针对这个问题,一方面对数据集做相似度分析,重新帅选样本,提高数据集的可靠性;另一方面做一个二次辨识雨、毛毛雨的模型,提高识别准确率。
Table 4. Accuracy statistics of rain test
表4. 雨测试准确率统计表
5.2. 雪样本测试
雪的测试样本67,800张,利用训练的最优模型对雪样测试集进行自动识别,识别结果毛毛雨601张,占总数0.8%;雨331张,占总数0.4%;雨夹雪3785张,占总数5.5%;雪63,083张,占总数93%,详细情况如表5雪测试准确率统计表所示。
雪的识别准确率是93%,其中错报率较高的是雨夹雪,达到5.5%。雪和雨夹雪的总识别率达到98.5%,说明雪和雨夹雪的样本相似度高,与毛毛雨、雨区分明显。下一步针对这个问题,做一个二次辨识雪、雨夹雪的模型来解决这个问题,识别准确率可以进一步提高。
Table 5. Snow test accuracy rate statistics table
表5. 雪测试准确率统计表
5.3. 综合分析
对雨、雪测试结果进行混淆分析结果如表6测试结果混淆矩阵统计所示,雨样本被准确识别的概率是62.7%,其中误判率较高的是毛毛雨,误判雪、雨夹雪的概率低;雪样本被准确识别的概率是93%,误判识率较高的是雨夹雪,误判雨、毛毛雨的概率极小。结果说明该识别模型能够有效区分雨、雪。下一步,对雨、雪再进行二次辨识,即可区分毛毛雨、雨夹雪。即模型第一步先识别雨雪,如果识别为雨,再进一步具体分析是雨还是毛毛雨;如果是雪,再进一步具体分析是雪还是雨夹雪。
Table 6. Confusion matrix statistics of test results
表6. 测试结果混淆矩阵统计
6. 结论
模型训练集和验证集平均准确率均达到86%,雨和毛毛雨的总识别率达到89.1%,雪的识别准确率是93%,说明利用深度卷积神经网络对降水现象仪数据生成的雨滴图进行自动降水现象识别方案可行,这一方法具有独创性,领先性。随着训练样本数据增多,模型进一步优化,平均准确率会进一步提高。利用深度学习图像分类技术来提高降水现象判定的准确性,从而提高整体自动化观测水平的目标可以实现。
参考文献