1. 引言
煤炭港口的粉尘一直是环保整治的难点。粉尘直接危害现场作业人员身体健康,造成难以估量的健康经济损失。在澳大利亚、南非等国家的大型煤炭港口,煤炭均是洗精煤,外含水量较高,基本没有扬尘。港口在作业过程中通过粉尘在线监测与堆场喷枪洒水相结合的方式控制煤尘,同时在皮带机头部设置洒水装置对皮带表层黏附的粉尘进行湿润和清扫即可解决粉尘污染难题。国内煤炭受各方面条件制约,煤炭外含水普遍较低,从产地到港口的运输过程中基本不采取措施,造成港口在作业过程中环保压力巨大。同时,国外在气候条件、煤种、煤质方面都与我国不同,其除尘经验很难满足我国港口特别是北方煤港的需要。随着环保要求的不断提高,必须通过生态港口建设解决难题,推动煤港转型升级,实现高质量发展 [1] [2] [3]。
近年来,黄骅港着力加强绿色生态港口建设,建成了生态水系统和环境监测网,实现了各水系统站点的远程集中自动化控制和堆场垛位的自动洒水控制,实现了粉尘、水质及管网的实时在线监测,并收集了现场大量的环境数据。如何做好煤炭港口的粉尘治理和含煤污水处理,提高清洁生产水平,促进港口绿色健康发展,已经成为黄骅港发展必须解决的问题之一。
为了抑制港口静置的堆垛扬尘,需要对堆垛进行洒水来抑制起尘。由于传统的洒水方式是由人工控制,有经验的工作人员凭借他们多年的工作经验来判断是否需要洒水,但是这种人工控制的方法经常不够精准、智能,如果洒水过少会造成煤炭含水率过低,煤堆扬尘,如果洒水过多会造成水资源浪费,而且会产生大量的含煤污水,造成二次污染,洒水过多或者过少都会对环境造成污染,很难掌握一个度来使洒水既不会使煤堆起尘又不会产生过量含煤废水。
鉴于此,本文以黄骅港为例,研究煤炭含水率变化的规律和智能洒水降尘的方法,通过建立煤炭含水率变化模型,利用模型来分析预测煤堆含水率的变化,从而制定智能的洒水降尘方法,自动调节煤炭含水率,减少扬尘和含煤污水污染。旨在提高污染预防能力、改善港口环境质量。
2. 问题描述
黄骅港智能洒水抑尘主要通过建立堆场含水率预测模型、堆场起尘预测模型和智能洒水模型,利用实时数据驱动,实现智能洒水抑尘。其洒水抑尘分为三步,第一步通过从黄骅港露天堆场的粉尘监测仪的数据库中获取露天堆场周围的实时气象数据,然后测得堆场中煤堆表层初始的含水率,将气象数据和初始含水率数据传入建立好的数据模型中,模型就可以根据此数据预测出下一时刻煤堆的含水率。第二步将预测出来的下一时刻的含水率的起动风速与实时的风速对比,如果此时的实时风速大于等于当前含水率的起动风速,说明当前风速会导致煤堆起尘,现在需要洒水,那么将数据反馈给现场的洒水系统,洒水系统开始洒水抑尘,达到智能抑制起尘的效果。第三步通过洒水量计算出煤炭含水率会变化多少,将变化后的含水率再当作此时的含水率跟气象数据一起输入到模型中继续预测下一时刻含水率。如此循环,便可以自动调节煤炭含水率,降低煤堆扬尘量和污水量,达到智能洒水降尘的目的。智能洒水抑尘的流程图如下(图1):
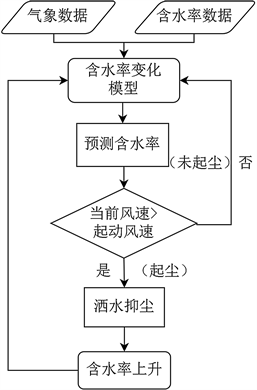
Figure 1. Flow chart of moisture content prediction and smart sprinkling and dust suppression
图1含水率预测与智能洒水抑尘流程图
3. 模型建立
港口煤垛含水率变化主要跟气象条件有关,如风速、温度、湿度、风向等。这些气象数据可以利用粉尘监测仪获取,而如何建立煤炭含水率和风速、温度、湿度、风向之间的关系的模型是关键,由于用来测量煤垛含水率而采取的煤样本是固定时间间隔的,从而根据气象数据来通过模型预测煤炭的含水率变化,因此可以采用LSTM模型来对煤垛含水率进行预测。
3.1. LSTM概述
时间序列预测(Time Series Forecasting, TSF) [4] 是一种利用历史数据预测给定序列的未来值的方法。在本文中,提出一种长短期记忆(LSTM)模型的深度学习方法,可以克服传统预测模型的局限性,做出准确的预测。LSTM是一种特殊的循环神经网络(Recurrent Neural Network, RNN)模型 [5]。图2为基于LSTM状态的计算模型。
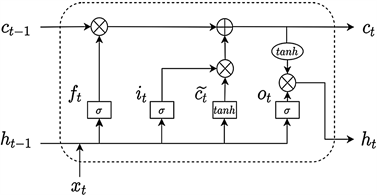
Figure 2. Calculation model based on LSTM state
图2. 基于LSTM状态的计算模型
LSTM有两种传递状态,一种是
(单元状态),另一种是
(隐藏状态)。利用LSTM的当前输入
和前一状态传递下来的输入
进行拼接训练,得到状态时步t的输入门
、遗忘门
、输出门
和候选记忆单元
分别计算如下:
(1)
(2)
(3)
(4)
式中,W为权重参数,b为偏差参数。
隐藏状态下的信息流动可由输入门、遗忘门和输出门控制,其元素范围为[0,1]。当前时间步长t将前一个时间步长记忆细胞的信息与当前时间步长候选记忆细胞的信息结合,通过遗忘门和输入门控制信息流动:
(5)
遗忘门控制上一时间步长的记忆单元
中的信息是否被传输到当前时间步长
的记忆单元,而输入门控制当前时间步长的输入
通过候选记忆单元流入当前时间步长的记忆单元
。如果遗忘门总是大约为1,而输入门总是大约为0,那么过去的记忆单元将总是存储在时间中,并传递到当前的时间步长。因此,LSTM在设计架构上解决了循环神经网络的梯度衰减问题,更好地捕捉了时间序列中时间步距的依赖性。
遗忘门控制上一时间步长的记忆单元
中的信息是否被传输到当前时间步长
的记忆单元,而输入门控制当前时间步长的输入
通过候选记忆单元流入当前时间步长的记忆单元
。如果遗忘门总是大约为1,而输入门总是大约为0,那么过去的记忆单元将总是存储在时间中,并传递到当前的时间步长。该设计解决了循环神经网络的梯度衰减问题,更好地捕捉了时间序列中时间步距的依赖性。
从存储器单元到隐藏状态
的信息流由输出门控制:
(6)
3.2. 工作流程
根据上文中的LSTM模型和算法,本文构建了一个预测煤炭含水率的深度学习算法框架。此深度学习的工作流程图如图3所示:
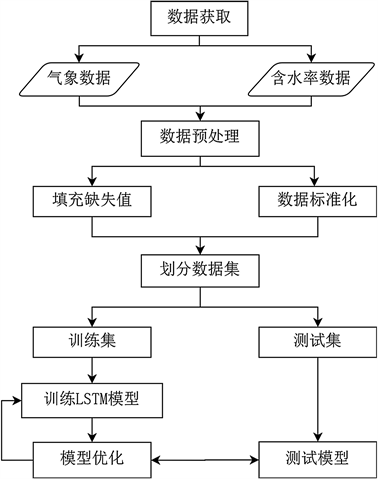
Figure 3. The workflow of building a model
图3. 建立模型的工作流程
3.3 算法流程
根据上文中的LSTM模型,本文构建了一个预测煤炭含水率的深度学习网络,此深度学习模型的算法工作流程如下:
1) 数据预处理。获取数据之后,由于含水率数据有可能测量错误,所以画出含水率数据的箱线图,把箱线图中的离群值当作异常值剔除。然后由于煤堆作业等其他因素,会暂停采样一次,这样就会使数据缺少一个数据样本,失去连续性,但是为了保证模型的准确性,需要每天的数据尽可能的连续,时间间隔相同,所以需要填充缺失值,本文使用的方法为插值法,取前后两个时刻的含水率平均值作为缺失数据当前时刻的含水率数据 [4]。
2) 据进行标准化处理,标准化之后数据的分布趋向于正态分布 [5],就不会因为各个数据不同的值域分布而对模型训练造成影响。这种方法基于原始数据的均值(mean)和标准差(standard deviation)进行数据的标准化,新数据 = (原数据 − 均值)/标准差。其公式为:
(7)
式中,
为数据的均值,
为数据的标准差。
3) 划分数据集。由于获取的数据集是按天采样的,所以把数据集以天为单位划分为若干个序列,以天为单位随机取出其中百分之八十的数据作为训练集,剩下的百分之二十作为测试集。
4) 模型设计。本文建立的模型是基于LSTM循环神经网络,根据上文的LSTM概述建立层数为4的神经网络,分别为输入层、两层隐含层和输出层,输入层神经元个数为5,隐含层的神经元个数为16,输出层神经元个数为1 [6]。
5) 训练模型。经过步骤(1)~(4)的准备,现在已经准备好了数据和模型,可以开始训练模型。把处理好的训练集数据输入到模型中,对模型进行训练,通过不断修改和调整学习率和隐含层神经元个数使loss值收敛到一个较低的值。
6) 测试模型。神经网络模型学习的效果需要通过误差大小来衡量,本文中采用均方误差MSE、平均绝对误差MAE (Mean Absolute Deviation)和决定系数R2(Coefficient of Determination)来对模型训练的效果做出定量的评价:
模型训练完成之后,把测试集数据输入到训练好的模型中进行测试,通过模型输出的预测值与真实值的比较,判断模型训练的效果,预测值与真实值之间相差越小模型精确度越高。
7) 模型优化。为了提高模型的准确性,需要对模型的学习率和权重等各个参数进行不断地调整,并可以使用L1正则化、L2正则化、Dropout等来防止过拟合。深层神经网络的参数量大,模型比较复杂,容易出现过拟合现象,而Dropout方法 [7] [8] 就是一种用来防止过拟合的技术,即在训练时以一定的比例随机使部分神经元失去活性,不会向前传递任何信息。本文使用的就是Dropout方法来防止过拟合。应用Dropout方法的神经网络结构示意图如图4所示。
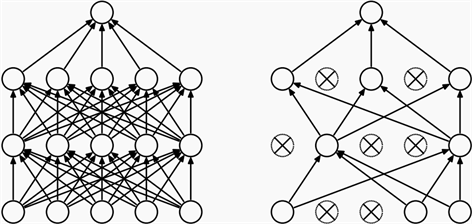 (a) Standard Neural Net (b) After applying dropout
(a) Standard Neural Net (b) After applying dropout
Figure 4. The neural network structure of the Dropout method
图4. Dropout方法神经网络结构
4. 实验结果
神经网络模型学习的效果需要通过误差大小来衡量,通过对训练集进行训练,模型的均方误差(MSE)的收敛曲线如图5所示。
由图5可以看出,经过大量训练之后模型的均方误差逐渐降低并稳定到较低值。模型训练完成之后,需要对模型进行测试,把测试集输入到模型中,通过模型计算出预测值,比较预测值和真实值之间的误差,来判断模型的准确率。通过测试,得到的模型的预测值和真实值之间的平均绝对误差MAE为1.03,LSTM模型的决定系数R²为0.85。
测试集通过LSTM模型计算出的预测值和真实值的部分数据如图6所示。由图6可以看出,LSTM模型对煤炭含水率的预测较为准确,对含水率变化趋势的预测与实际相符,没有出现位移偏差,预测值与真实值的误差较小,绝对误差的最大值与最小值分别为4.68和0.01,绝对百分比误差的最大值与最小值分别为107%和0.1%,而且没有出现波谷过低和波峰过高,对波峰和波谷的预测较为准确。
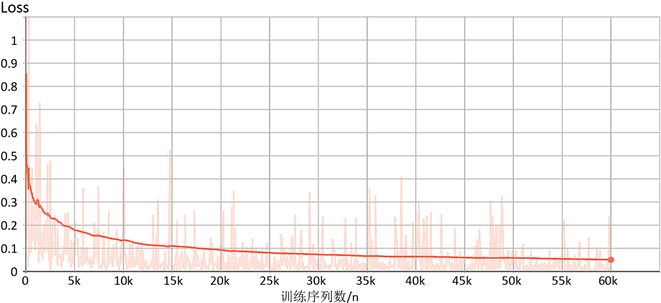
Figure 5. MSE convergence curve of the model
图5. 模型的MSE收敛曲线
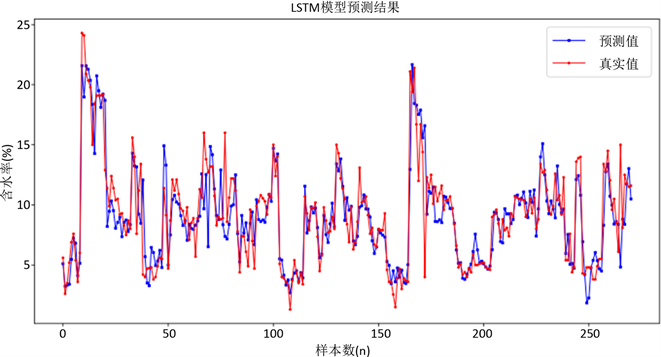
Figure 6. Comparison between the predicted value of the LSTM model and the true value
图6. LSTM模型的预测值与真实值的比较
通过本文建立的LSTM模型,我们根据当前煤炭含水率和气象数据可以预测出下一时刻煤炭的含水率,通过下一时刻含水率对应的起动风速和实际风速进行对比,如果实际风速大于当前风速,那么控制洒水设备进行洒水抑尘,洒水之后,通过洒水量可以计算出煤炭含水率变化后的值为多少,把此含水率当作当前含水率跟气象数据一起继续使用模型进行预测,就可实现自动洒水调节煤炭含水率,抑制煤炭起尘,实现智能洒水降尘。
5. 结论
本文通过建立了基于LSTM循环神经网络的煤炭含水率变化模型,提出了制定露天煤场智能洒水的方法,据此方法实现了煤堆含水率根据温度、湿度、风速、风向变化的自动调整。通过建立的LSTM模型,根据当前煤炭含水率和气象数据可以预测出下一时刻煤炭的含水率,通过下一时刻含水率对应的起动风速和实际风速进行对比,当实际风速大于起尘阈值风速,那么控制洒水设备进行洒水抑尘,洒水之后,通过洒水量可以计算出煤炭含水率变化后的值为多少,把此含水率当作当前含水率跟气象数据一起继续使用模型进行预测,就可实现自动洒水调节煤炭含水率,抑制煤炭起尘,从而实现智能洒水降尘。
研究表明,与传统的人工控制洒水相比,本文提出的方法预测模型精准,对露天堆场实现智能洒水抑尘,自动调节煤炭含水率,降低露天堆场的扬尘量,具有实用意义,为建设绿色生态港口提供了理论方法借鉴。
基金项目
感谢黄骅港堆场智能洒水管控技术研究(U03462)项目基金对本项目的资助。