1. 引言
配电变压器的状态评价是及时准确的掌握配电变压器的工作状态,对部件及整体进行健康状态的评价,是状态检修的核心。其旨在加强对配电变压器状态的检测和监视,提升配电变压器的运行可靠性,从而提升电网安全运行水平 [1] 。
本文将对配电变压器状态评价所涉及到的相关理论知识进行研究,主要包括模糊理论、模糊综合评判的具体评价方法及步骤,粗糙集的基本理论、方法以及粗糙集方法的改进等。
2. 模糊综合评判方法
模糊综合评判分析方法就是把待考察的模糊对象以及反映模糊对象的模糊概念作为一定的模糊集合,建立适当的隶属函数,并通过模糊集合论的有关运算和变换,对模糊对象进行定量分析。综合评判是对多种因素所影响的事物或现象做出总的评价,模糊数学是用数学的方法研究和处理客观存在的模糊现象,模糊综合评判就是借助模糊数学对多种因素所影响的事物或现象做出总的评价 [1] [2] [3] [4] 。
2.1. 模糊集合的基本概念
模糊集合理论是为解决复杂系统的不确定性而提出的工具。模糊集合的定义是:论域X上的一个模
糊集合A是指:对于论域X中的任一个元素
,都指定了闭区间
中的一个数
与之对应,
就是x对X的隶属度。这意味着定义了一个映射
,这个映射称为模糊集合的隶属函数。隶属函数的定义是:用于描述模糊集合,并在闭区间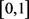 上可以连续取值的特征函数。
上可以连续取值的特征函数。
隶属函数用
表示,其中A表示模糊集合,而x是A的元素。隶属函数满足:
。模糊理论的基本概念就是隶属函数。在表示普通集合时,使用特征函数来表示其边界;而特征函数只能取离散值0和1,模糊集合则用隶属函数来表示边界,隶属函数则可以取0至1之间的连续值。一个元素的隶属函数值为0,说明该元素不属于该集模糊集合;隶属函数值为1,说明该元素完全属于该模糊集合;隶属函数值介于0至1之间,则说明元素属于该模糊集合的程度。
2.2. 模糊综合评判的步骤
模糊综合评判是在考虑多种因素的影响下,运用模糊数学工具对事物做出综合评价。模糊综合评判的数学模型通常采用多级评判模型。一个二级评判的模型如式1.1所示。
(1.1)
式中
为广义的模糊算子。对于因素集U上的权重模糊向量
,通过R矩阵变换为评判集V上的模糊集
,于是
构成一个综合评价模型,它类似如图1所示的转换器,若输入一个权重分配
,则输出一个综合评价
。
下面给出模糊综合评判的具体步骤。
1) 确定被评价的对象X。这里表示为需要评价的配电网某变压器。
2) 建立因素集U,也就是评价指标体系。
设被评价对象X有n个影响因素,分别为
,则因素集
,因素集对应的因素向量则为
。配电变压器的结构较复杂,使用多级的模糊综合评判模型,将各状态量分成属性层和因素层。
3) 建立表示评价结果等级的评价集V。
设
为评价等级,等级数为m,则评价集
。本文中将配电变压器的运行状态和状态
量的情况分为四种,分别为“正常”、“注意”、“异常”和“严重”。状态量最严重的状态即为“严重”,以下依次分等级。因此评价集
(1.2)
4) 确定权重系数集W
权重集是指某因素对被评价对象的重要程度(即权重),设
的权重分别为
,且满足如下关系式
(1.3)
3. 基于粗糙集理论的权重系数确定方法的研究
本节将探讨对评价指标权重系数确定方法的研究现状,提出结合层次分析法和粗糙集理论方法作为配电变压器状态量权重系数的确定方法,给出确定权重系数的一般算法,再结合权重系数的现实意义对权重系数的一般算法进行改进。
3.1. 状态量权重系数的确定方法分类
根据确定权重系数时原始数据来源以及计算过程的不同,将评价指标权重系数的确定方法分为主观赋权法和客观赋权法。
本文选择层次分析法确定评价指标体系的属性层各部分对目标层的权重系数,虽具有一定主观性,但符合现阶段配网设备的相关要求。选用粗糙集理论确定各因素层的状态量权重系数。粗糙集理论既考虑了评价指标的历史数据,又可以通过工程实际和专家意见判定历史数据中的评价结果,能将主观赋权法和客观赋权法进行结合,反映了主客观两个方面,因此可以实现合理准确的确定评价指标权重系数。
3.2. 基于粗糙集理论权重系数的确定方法
权重系数指的是评价指标(条件属性)在整体评价中的相对重要程度。基于粗糙集理论确定权重系数就是将权重系数确定问题转化为粗糙集理论中属性重要性的评价问题。因此,确定权重系数的思路 [5] [6] 大体是从决策表中去掉一种属性,观察分析在去掉该属性后决策表中分类规则的变化情况。如果去掉该属性后分类规则变化较大,则说明该属性对分类的影响强度大,即重要性高,权重系数大;反之,则说明该属性的影响强度小,相对于其他属性而言重要性低,权重系数小。
3.2.1. 粗糙集理论确定权重系数的一般算法
结合粗糙集理论的基本概念和确定权重系数的基本思路,说明确定权重系数的一般算法 [7] [8] [9] [10] 为
1) 决策表的建立
论域中的数据集合通过决策表来描述,即是在对数据进行离散化后制成二维知识表达系统。其中条件属性为
,条件属性集为C,决定属性为
,决定属性集为D;
2) 依赖度的计算
计算决策属性D对条件属性C的依赖度为
(2.1)
对每个条件属性Ci,计算决策属性D对条件属性
的依赖度为
(2.2)
3) 重要度的计算
根据依赖度得出第i个条件属性关于D的重要度
(2.3)
若条件属性Ci的重要度越大,则说明去掉条件属性Ci后相应的分类变化较大,该属性的强度较大,否则,该属性的强度较小。
4) 权重系数的计算
通过对重要度的计算,可得出每个条件属性的权重系数
(2.4)
权重系数的实质是将重要度进行归一化,因此将每个条件属性的权重系数相加,其结果应为1。权重系数的大小即是反映条件属性的相对重要程度,某个条件属性的权重系数越大,则该条件属性重要程度越大,对论域整体的影响也越大。
3.2.2. 改进后的权重系数的确定算法
用以上确定权重系数的一般算法计算得到的权重系数容易为0。而条件属性的权重系数应该是客观存在的,即使影响的程度很小其权重系数也应该为较小的数值。特别是对实际情况中存在具体意义的条件属性,其重要性必定存在。因此对以上方法进行一定的改进 [11] [12] [13] [14] ,引入了条件熵的概念,使每个条件属性的权重系数值都不为0。改进后的权重系数确定算法如下。
1) 条件熵的计算
在决策表
中,
,
,
为条件属性集,
为决策属性集,则D相对于C的条件熵
(2.5)
条件熵
说明了系统中条件属性Ci自身的重要程度。
2) 改进后重要度的计算
在决策表
中,
,
,则条件属性Ci的重要度
(2.6)
其中,
。
重要度
说明了条件属性Ci在整个条件属性中的重要程度。
3) 改进后的权重系数的计算
在决策表
中,
,则条件属性Ci的权重系数
(2.7)
根据文献 [15] 的证明,上述条件属性重要度具有单调上升的性质,条件属性Ci的权重系数W(Ci)始终是大于0的,因此保证了权重系数能真实反映条件属性的现实意义。
4. 实例分析
表1是一个判断是否发生变压器油绝缘故障的决策表。通过对受潮、油温、渗漏油及故障情况的6组记录,利用确定权重系数的一般算法和改进算法分别确定受潮、油温、渗漏油的权重系数,并分析三者对发烧情况的影响作用。

Table 1. Oil insulation fault diagnosis decision table
表1. 油绝缘故障诊断决策表
4.1. 决策表的知识分类
决策表的论域
,条件属性集为
,决策属性集为
,其中,决策属性d为油绝缘故障。
论域U对受潮C1、油温C2、渗漏油C3进行分类
则论域U对所有条件属性C的分类为
论域U对决策属性D的分类为
由此可以得出决策属性D的条件属性C-正域为
4.2. 基于一般算法确定权重系数
决策属性D的条件属性C正域为
,依次去除条件属性,论域对条件属性C-Ci的分类分别为
由式(2.1)计算决策属性D和条件属性C之间的依赖度为
决策属性D对条件属性C-Ci的正域
由式(2.2),计算决策属性D对条件属性C-Ci的依赖度为
则由式(2.3),分别计算出每个条件属性Ci关于D的重要度为
则由式(2.4),得到各条件属性Ci的权重系数
即受潮的权重系数为0,油温的权重系数为0,渗漏油的权重系数为1。
4.3. 基于改进算法确定权重系数
由式(2.5)可得到D相对于C的条件熵为
对条件属性
,由
得到D对C1的条件熵为
去掉条件属性C1后,由于
得到
同理,可计算得到D对条件属性C2和C3的条件熵分别为
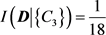
去掉条件属性C2和C3时,有
同时,
,
,可得到
因此由式(2.6)计算,可得到条件属性C1、C2、C3的重要度分别为
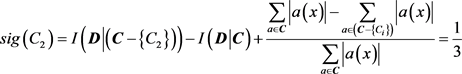
由式(2.7)可得到条件属性C1、C2、C3的权重系数分别为
即受潮的权重系数为0.3125,油温的权重系数为0.375,渗漏油的权重系数为0.3125。
4.4. 对比分析
采用一般算法确定权重系数时,受潮和油温的权重系数为0,渗漏油的权重系数为1。表明去掉受潮和油温对整个决策表不会产生影响,可以进行约简,而渗漏油对是否的发生油绝缘故障起决定性作用。观察决策表可看出,当渗漏油为“少量”时,决策属性中既有“是”,也有“否”,因此单凭渗漏油这一条件属性并不能准确决策出是否发生油绝缘故障,受潮和油温也会对是否发生油绝缘故障产生影响。因此使用一般算法确定权重系数会产生较大的误差,与实际不符。
采用改进算法确定权重系数得到三个条件属性受潮、油温和渗漏油的权重系数均不为0,说明三者都是必要不可去除的,对判定是否发生油绝缘故障都有影响,这与实际情况相符。因此用改进后的权重系数确定方法可以避免权重系数为0的情况,避免重要属性被去掉,保证了每个条件属性在决策中都有意义。
综合以上分析,可以得到采用改进后的权重系数的确定算法更能说明实际问题,更具有客观现实意义。
5. 总结
本文通过研究分析配电变压器状态评价所涉及到的相关理论知识,引入了模糊综合评判方法,并对评价方法的过程进行了详细的介绍,通过比较评价指标权重系数确定方法的优缺点,提出了确定权重系数的一般方法和改进方法,通过实例的分析和计算,得出在配电变压器状态评价中计算状态量权重系数应采用改进的基于粗糙集理论的权重系数确定方法。