1. 引言
数据挖掘是从大量的数据中挖掘出隐含的、未知的、用户可能感兴趣的和对决策者有潜在价值的知识和规则 [1] 。常用的数据挖掘方法主要有以下几种,分类与聚类分析方法、统计方法、偏差分析方法、决策树与回归树方法、关联规则方法等 [1] - [7] 。本文讨论将聚类分析与关联规则两种方法结合应用的技术,以实现更好的数据挖掘效果。
聚类分析是研究数据之间物理的或逻辑的相互关系的技术,通过一定的规则将数据集划分为在性质上相似的数据点构成的若干个类簇。聚类分析的结果可以揭示数据之间的内在联系与区别,发现数据库中分布的一些深层的信息与知识,进一步研究,可以概括出每一类的主要特征。也可以把着眼点放在某些特定的类上进行进一步的分析 [8] [9] 。
关联规则反映一个事物与其他事物之间的相互依存性和关联性。如果两个或者多个事物之间存在一定的关联关系,那么,其中一个事物就能够通过其他事物预测到。关联规则挖掘就是为了在数据集中发现这些关联关系,是数据挖掘技术中最先提出的问题之一,也是数据挖掘的一个主要研究方向。关联规则由Agrawal、Imielinski和Swami在1993年提出 [2] [10] ,次年,Agrawal和Verkamo提出了关联规则挖掘的经典算法Apriori [11] 。本文后面章节的关联规则实验,即采用了该算法的改进版。
2. 聚类联合关联规则的挖掘技术
聚类分析和关联规则是数据挖掘中两个非常重要且具有各自代表性的典型方法——聚类分析主要实现数据挖掘的描述功能;而关联规则主要实现数据挖掘的预测/验证功能。
2.1. 聚类分析
聚类分析是一种寻求数据的自然聚集结构的重要方法,增强了人们对客观现象的认识。聚类应用的意义,主要表现在处理大量的、繁杂的、属性众多且没有类标志的数据。这些没有类标志的数据经过聚类处理后,将根据其内在特征的相似性,自动聚集为若干类簇,类内对象相似度较大,而类间对象相似度较小。
聚类分析的基本方法是,同类样本的离差平方和应当较小,而类之间的离差平方和应当较大。假定已经将n个样本分成了k个类
,用xit表示Ct中的第i个样本的特征值向量,nt表示类Ct中的样本个数,
表示Ct的重心,则Ct中样本的离差平方和为:
全部类内离差平方和为:
当n很大时,要给出全部样本所有可能的聚类,并从中选择出使S达到极小的聚类方案是极其困难的。于是,Ward提出了这种聚类方法,采用离差平方和法,样本之间的距离采用欧氏距离法 [12] 。聚类分析实现的算法现在已经有很多,本文采用了模糊聚类和人工神经网络聚类等两种方法 [13] [14] 。
聚类结果是使数据挖掘具备识别群功能。
2.2. 关联规则
关联规则是描述数据库中数据项之间存在潜在关系的规则。设
为全体数据项集合,则关联规则可以形式化定义为:
,其中
,且
。项集之间的关联表示:如果X出现在一条交易中,则Y在这条交易中同时出现的可能性比较高。
“可能性比较高”的界定方法,则采用支持度和置信度来表述:
规则
的支持度定义为X和Y同时出现的可能性,表示为
;规则
的置信度定义为全体事务集D中包含X的同时也包含Y的可能性,表示为
。当支持度和置信度的值都大于给定的相应阈值时的规则称为关联规则 [1] [8] 。
下面给出关联规则的基本算法Apriori的伪代码 [15] :
L[1]={large 1-itemsets};
for (k=2; L[k-1]≠Φ; k=k+1) do
C[k]=apriori_gen(L[k-1]); //构造候选项集
for all transactions t∈D do
C[t]=subset(C[k], t);
//搜索事务t中包含的候选项集
for all C∈C[t] do C.sup=C.sup+1; end for
//计算支持数
end for
L[k]={ C∈C[k] | C.sup>=minsup};
//得到K阶大项集
end for
L=U[k] L[k];
其中候选项集的生成是Apriori算法的核心,通过Apriori_gen函数运算实现。描述如下:
insert into C[k]
select P[1], P[2], ∙∙∙, P[k − 1], Q[k − 1]
from L[k − 1] P, L[k − 1] Q
where P[1]= Q[1], ∙∙∙, P[k − 2] = Q[k − 2], P[k − 1] < Q[k − 1]
对构造的候选项集进行削减:如果k阶候选项集C的某个k-1阶子集不中L[k − 1]中,那么C就不可能是大项集,需要将其从候选项集C[k]中删除。
for all itemsets C Î C[k] do
for all (k − 1) itemsets S of C do
if (SÏL[k − 1]) then delete C from C[k]
关联规则可以发现聚类之间的关系,挖掘出样本和聚类之间的关联规则和潜在知识。
2.3. 联合运用
一般地,聚类分析中,样本的属性值是连续型的;而关联规则挖掘中样本的属性值是离散型的。二者对样本数据的处理方法和分析结果的输出形式有很大差异性和互补性。表1对本文所采用的两种聚类方法和一种关联规则方法进行了比较。
从表中容易发现,将聚类分析与关联规则结合起来,可以取得更好的挖掘效果,后面的实验完全证明了这一点。
二者联合运用的具体方法是,先对样本集进行聚类分析,通过聚类把整个样本集分成不同子集,使样本实体获得各自的类别信息;再对这些带有分类属性的样本进行关联规则挖掘,使得挖掘运算有效降维且具有更好的挖掘目标。
3. 实验数据与方法
3.1. 样本数据
用于编程实验的数据来自河南大学本科生的某次考试(http://218.196.195.205/admin/ks/ vbks.asp)。试卷包括4个大题(题号分别以A、B、C、D标识),每题满分25分,卷面分值100分。全体考生平均成绩77.9分,符合正态分布。不失一般性,本文实验中随机抽出得分比较接近均值的100名考生的考试数据进行挖掘分析。样本数据参见表2。

Table 1. Function contrast of clustering and association rule
表1. 聚类与关联规则功能对比
表2. 样本数据
3.2. 数据变换
先将样本数据整理成便于聚类的形式,例如,将原始数据中比较复杂的学号和题号替换为容易运算的符号,然后进行标准化变换。本文使用了离差变换和标准差变换 [9] 。
3.3. 聚类分析
对变换后的样本数据分别进行模糊聚类和自组织神经网络聚类,然后运用F检验,自动取得最佳聚类方案 [13] 。实验中,两种聚类方法获得的最佳聚类结果完全一致,均为5类。聚类结果参见图1。
3.4. 关联规则挖掘
经过3.3所述的聚类分析之后,再对已具备类别(图1中最右列)的样本数据进行关联规则挖掘分析,将使挖掘运算更为方便,且规则指向性更明确、更容易理解。
本文采用改进的Apriori算法进行关联规则分析,输出相应的关联规则,参见图2。
4. 结果与讨论
聚类结果将100个考生样本分为5类,其中第1类23个,第2类22个,第3类4个,第4类19个,第5类32个。通过表3的比较,大致可以了解每类的主要特征。
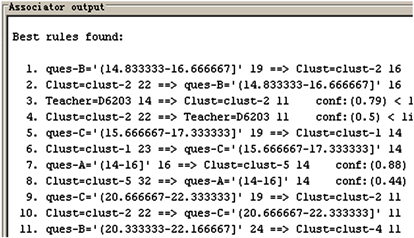
Figure 2. Data mining results of association rules after clustering
图2. 聚类后进行的关联规则数据挖掘结果
Table 3. Clustering results analysis of ample data
表3. 样本数据聚类结果分析
根据表中数据容易发现,第1类考生C题得分较低;第2类考生B题得分较低;第3类考生四个题得分均匀;第4类考生D题得分较低;第5类考生A题得分较低。但这只是对聚类意义的大致解读,缺乏准确和全面的理解。
与文献 [16] 等许多基于聚类的分析实验相比较,那些只做到本步骤层面的分析,并不能直接得到具有知识层面的信息和情报,尚需专家对聚类结果进行人工解析才可以理解聚类分析的意义。
基于聚类的关联规则挖掘分析,则将在聚类的基础上得出一系列更为明确和直接的分析结果。例如,在图2中,挖掘结果的前4条规则就明确给出了如下关联规则:
ques-B = 14.8-16. 7 ==> Clust = clust-2
Clust = clust-2 ==> Teacher = D6203
其意义解释为:
第B题得分介于14.8~16.7 (偏低)的考生,被归入“clust-2”类;而“clust-2”类的任课教师是编号为“D6203”的老师。
这一规则明确提示我们,编号为“D6203”的教师在第B题的教学方面存在明显问题,需要改正。
如果继续使用关联规则对相关数据集进行挖掘,可能找出“D6203”老师在B题教学方面存在问题的原因,从而为督促该教师改善和提高教学效果提供有力的技术依据与支撑。
同时,由于关联规则挖掘是在样本取得聚类的基础上进行的,因此,不仅使得挖掘得到有效降维,降低了计算复杂性,而且挖掘的目标更为明确,所挖掘到的规则直接关联具体的类别,其指示意义更为明显和直接。这是不进行聚类分析而直接使用关联规则所不得达到的。
5. 结语
按照传统和粗放的考试成绩分析方法,本文所分析的100位考生应属于同一类(成绩都接近均值),但聚类分析却可以通过每个样本属性的特征值,更加深刻和准确地根据每个考生知识点和能力点掌握情况的差异之处,并将其划分为若干类,为进一步挖掘类之间的关系打下基础;而在聚类之后进行的关联规则挖掘,则更进一步发现了聚类形成的原因和聚类之间的关系等潜在的知识。聚类分析和关联规则的联合运用取得了更好的挖掘效果。本文所述实验大部分已经过多个大样本集的实际挖掘应用,实践证明,聚类分析与关联规则联合挖掘技术具有稳定有效的应用价值和非常广阔的应用前景,值得进一步研究推广。
基金项目
感谢河南省教师教育课程改革研究项目(2017)的资助。
NOTES
*通讯作者。