1. 引言
随着互联网行业迈入大数据时代,网络为人们提供了海量的信息资源,极大程度地满足了用户对各类信息的需求。在带来巨大便利的同时,网络信息过载问题也变得日益突出,用户在海量信息中找到自身所需信息的需求变得更为迫切。
在这样的背景下,信息推荐技术作为信息过滤的有效手段,逐渐成为计算机学术和应用领域的热门研究对象,已经在互联网系统中被广泛地使用 [1] 。推荐系统针对在用户没有明确的需求场景的情况下,通过采集用户历史信息和推荐物品的特性,分析其中的关联特性,推测用户对潜在物品的个性化偏好情况,进而向用户推荐最优选择,帮助用户选择所需要的产品,在极大方便网站用户的同时,也有效提高了网站的运营效果和服务质量。
在众多推荐技术中,协同过滤算法是当前被广泛应用较为成熟的一项技术 [2] 。协同过滤算法认为有近似选择偏好的用户一般可能会喜欢相同的物品,具体可以分为基于用户的、基于项目的、基于模型的三类协同过滤算法 [3] 。协同过滤算法的优点首先是能够过滤那些表达复杂的描述型内容,从而解决了难以进行自动内容分析信息过滤问题,另外还具有推荐新信息的功能。然而,协同过滤算法在数据量不断增大的情况下也有其问题和局限性,典型的就是评分矩阵稀疏性问题和冷启动问题,围绕这些问题,近年来学术界进行不断深入研究,提出了很多有效的改进方案 [4] 。
本文选取结合用户对产品评价内容来提高算法的准确性。不论是在资讯传媒还是电子商务领域,用户往往会发表相关的评论,在这些评论信息里,同时还有隐性的肯定或否定的态度和对产品的关注度等信息,这些评论观点对用户和网站而言都具有重要的价值,将这些信息提取出来,便可为用户更为精准地推荐合适的对象。
针对当前推荐算法中存在的一些问题,本文提出通过基于用户特征分析和产品特征分析结合的改进混合推荐算法。用户初次进入系统后,首先通过ICT-CLAS技术对评论文本进行分词和词性标注,再将特征词归纳量化,计算物品特征权重,完成数据第一步采集处理;下一步基于用户行为计算用户偏好特征值;结合传统协同过滤推荐算法,通过邻居用户聚类,计算用户对其它项目的评价得分,向用户推荐得分最高的项目内容。经过实验,结果表明该方法可以提高推荐的精确度。
2. 系统概要设计
2.1. 整体框架与步骤
基于特征偏好分析的改进混合推荐算法将用户-产品评分数据作为初始数据源,把整个推荐过程分为以下几大步骤:
(1) 数据初步处理:对大量评论数据采用汉语词语分析方法对其进行分词,同时注明词语的词性;
(2) 特征词归纳与量化:筛选出频率达到特定阈值的特征词,对其进行剪枝处理,过滤掉不符合要求的特征词;量化特征词维度上的评价,并按照特定公式计算其权重;
(3) 构建用户偏好向量:构建表示用户特征偏好的向量,并按照聚类算法的思想计算用户的相似邻居集;
(4) 产生推荐内容:计算用户评分相似度和特征相似度的值,将评价分数最高的项目推进给用户。
简明系统框架如图1所示。
2.2. 相关数据
用户的集合表示为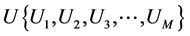 ;电影产品的集合表示为
;电影产品的集合表示为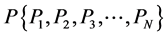 ;产品特征集合表示为
;产品特征集合表示为 ;用户特征集表示为
;用户特征集表示为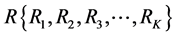 ;用户-产品评分的矩阵用表示为矩阵RM*N,其中Rij表示用户Ui对产品Pj的评价得分;产品-特征关联矩阵表示为矩阵WS*N。其中rij表示特征关键词Fi对产品Pj的权重比例得分。
;用户-产品评分的矩阵用表示为矩阵RM*N,其中Rij表示用户Ui对产品Pj的评价得分;产品-特征关联矩阵表示为矩阵WS*N。其中rij表示特征关键词Fi对产品Pj的权重比例得分。
产品-特征评分矩阵表示为矩阵WS*N,矩阵示意图如图2所示。
3. 新型混合推荐算法
特征偏好分析通过在文本中挖掘用户评论内容的隐含的偏好,解决推荐算法准确性和局限性的问题。
步骤1:评论数据的初步分析处理;算法首先采用汉语词法分析算法ICT-CLAS(Institute of Computing Technology, Chinese Lexical Analysis System)对互联网上获取的电影评论文本进行中文分词 [5] 。ICT-CLAS是中国科学院计算技术研究所研制的一种词语分析系统,其主要功能包括词汇分词、词性标注等。系统
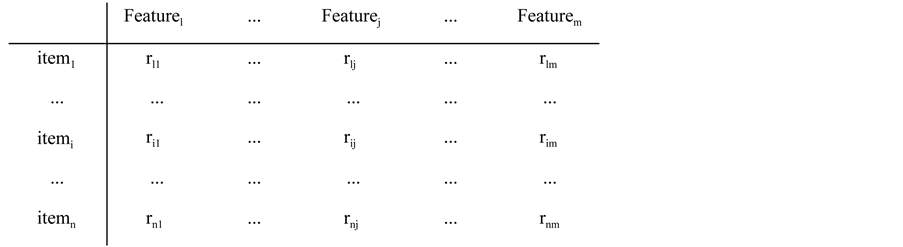
Figure 2. Schematic diagram of product feature matrixes
图2. 产品特征矩阵示意图
技术的基本思路是首先进行原子切分,然后在此基础上进行N-最短路径切分,找到前N个最符合的切分结果,生成二元分词表,进一步进行词性标注并完成分词步骤。ICT-CLAS系统是当前主流的汉语词法分析器。
利用汉语词语分析算法将词语注明词性,如名词、动词、形容词、副词。通过大量观察统计并设定阈值对数据进行过滤可以得出结论,特征词一般为名词和动词,情感词一般为形容词或副词,由此完成候选词中特征词与用户情感偏好词数据的采集分析。
步骤2:特征词的过滤与归纳;物品特征一般指评论中被提到频率较高的描述物体性质的名词 [6] 。经过多次剪枝操作的尝试,得到适中的阈值标准,以此标准对候选词进行剪枝处理,对和物品性能无直接关系的候选项和小于指定阈值标准的候选项过滤,抽取和对象特征直接相关的情感词,以此提高推荐结果准确性。
具体的过滤结果如表1所示。
由于一种物品的特征词数量往往很多,导致建模后矩阵的维度过高计算繁琐复杂,因此可讲过滤后的特征词归纳为几个大的类型,以此简化后期计算。本文从用户评论中提取的电影特征词根据相似性可化为几类,具体划分情况如表2所示。
步骤3:构建物品特征向量;归纳总结特征词之后,下一步是构建量化物品特征向量,将每个特征维度进行五分制评分,多个特征维度上的平均分表达用户对物品的评价倾向,最喜欢为5分,最不喜欢为1分。一个产品在特定属性上的特征值由全体用户在该特征上的共同评价决定。从而得到产品在若干个特征维度上的评价分数 。部分产品特征计算结果如表3所示。
。部分产品特征计算结果如表3所示。

Table 1. Product feature words table
表1. 过滤后部分电影特征词
Table 2. Movie level division table
表2. 电影特征词划分表
Table 3. Movie level scores table
表3. 电影大类评分表
步骤4:计算特征词权重;通过TF-IDF技术(Term Frequency-Inverse Document Frequency)以基于特征词频率的向量形式表示文本,当关键词在全部文档中出现的频率较低同时在部分评论中出现的频率较高,特征词权重较高 [7] 。将网页内容特征和用户资料模型相结合,可将最终的函数定义为:其中D为语料库中的文件总数,DF(t)为单词在文档中出现的频率:
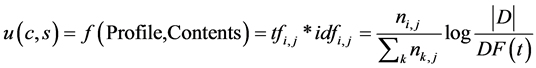 (1)
(1)
利用公式(1)可得到u的数值,并将较大的数值作为更高权重的参考特征 [8] 。
步骤5:构建用户偏好向量;传统的推荐算法从单一维度上只考虑用户对物品的整体评分,推荐的灵活性和准确性不高。由于不同用户对产品的关注层面各有不同,因此本文提出一种基于用户多维度上偏好的向量推荐方法,而且用户的爱好随着时间变化会产生变化,通过不断地学习,系统可以及时更新用户的特征向量。定义矩阵R为用户的偏好向量。 ,ri用户对某一大类特征的偏好程度参数。用户的特征向量计算公式为:
,ri用户对某一大类特征的偏好程度参数。用户的特征向量计算公式为:
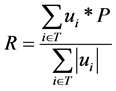 (2)
(2)
其中P表示产品的特征向量。用户对产品综合评分为偏好向量R与产品大类向量G(f)的乘积 [9] 。
 (3)
(3)
步骤6:通过聚类计算用户相似度;聚类算法通过将对象集合分为不同的子集,相同子集中的对象具有较高的相似性,本文通过这种思想将相似度高的用户放到一个子集中,以此降低用户邻居集的计算量 [10] 。随机从用户集合中选取k个对象作为初始子集的中心点;计算用户特征向量与这些子集的距离,依据最小距离原则重新划分特征向量;重新计算每个子集的均值作为子集的中心点;重复前两部完成用户特征向量聚类。
用户的相似度可以分为两类——用户偏好相似度和用户评分相似度 [11] 。用户偏好相似度可以用夹角余弦值来进行计算,余弦相似度计算用户偏好向量的相似度公式为:
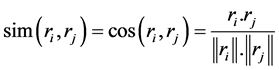 (4)
(4)
其中rirj表示用户的偏好向量,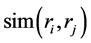 表示两者之间的偏好相似程度,计算结果越大表示两个用户偏好约为接近 [12] 。
表示两者之间的偏好相似程度,计算结果越大表示两个用户偏好约为接近 [12] 。
由于偏好相似的用户具有相似的评分行为,所以通过用户对同一物品的评分,计算用户相似度,选用最为常用的皮尔森相关系数公式(Pearson Correlation Coefficient),公式如下:
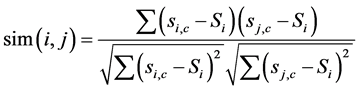 (5)
(5)
其中si,c和sj,c表示用户i和用户j对同一评分项目c的评分,SiSj表示用户的平均对物品的平均评分 [13] 。
步骤7:综合评分计算和物品推荐;利用基于用户协同过滤算法,通过与目标用户相似的邻居集合计算目标物品对特定商品的评分,选择相似度较大的邻居用户形成邻居集,采用加权平均的策略,根据公式(7),将邻居集中对项目的评分加权计算出推荐结果,
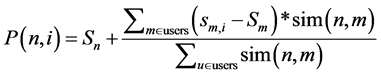 (6)
(6)
其中Sn表示项目平均评分,sm,i表示邻居用户对该项目i的评分,Sm表示邻居用户所有评分均分,sim(u, m)表示目标用户u和邻居用户m的综合相似度 [14] 。将推荐预测评分最高的前k个对象推荐给用户。
4. 实验分析
实验过程
平均差值公式是目前评价一个推荐系统的性能的主流评价标准,把实际评分与预测得到的评分求绝对平均误差MAE(Mean Absolute Error)来比较预测分值与实际分值之间的偏差程度,从而判断推荐的准确性,当平均差值越小表示推荐系统的效果越好 [15] 。算法预测评分集为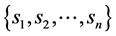 ,用户实际评分集为
,用户实际评分集为 ,平均差值的公式如下 [16] ,
,平均差值的公式如下 [16] ,
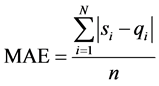 (7)
(7)
通过网络爬虫程序爬取某互联网电影资料库中用户对1299个产品的评价信息和评分数据,将数据随机分为两个部分,其中80%归为训练集,20%归为测试集。实验结果表明,传统的基于用户或基于内容协同过滤算法绝对平均误差MAE值较大,推荐精度较低,相比较之下,新的推荐算法MAE值较小,推荐精确度有明显提高,实验数据如图3所示。
基于特征偏好分析的新型混合推荐算法的优势在于,首先对评论文本进行分析,提炼出其中的关键特征信息,核心思想是综合利用用户和产品两方面的特征分析方法,再通过基于用户协同过滤算法处理得到最终数据,因此新算法与传统推荐算法相比有明显优势,特别是在用户目标数较低的情况下,精确度提升效果更为明显。

Figure 3. Comparison of algorithm recommendation accuracy
图3. 算法推荐准确度比较
5. 结论
本文提出了一种基于特征偏好分析的改进混合推荐算法,计算物品特征向量和用户特征偏好向量,通过与目标用户相似的邻居用户聚类,利用协同过滤推荐算法,将评分最高的物品推荐给用户,缓解了传统推荐算法中的矩阵稀疏性问题和冷启动问题。实验结果表明,基于特征偏好分析的改进混合推荐算法有效提高了推荐结果的准确性。