1. 引言
在“双碳”目标提出后,如何改善传统能源结构以有效提升新能源渗透率成为亟待解决的焦点问题。而微网作为一种包含可再生能源等的综合技术,对于推动电力系统的低碳化具有重要意义 [1] [2] 。随着微网技术和综合能源的推广应用,热电联供型综合能源微网的数量不断增加,同时地理位置毗邻的微网可以相互连接形成热电联供型微网群系统,通过多能互补和能源的梯级利用,有效提升了能源利用率,大大降低了污染排放,为建成清洁低碳的能源体系发挥重要作用。
然而热电联供型微网群系统规模较大,其优化问题涉及到众多变量及约束,同时内部存在多种异质能源之间的耦合关系,难以实现高效精确求解,对调度优化问题提出了挑战,研究热电联供型微网群优化调度方法十分必要。目前针对热电联供型微网群系统优化策略的求解,传统方法主要包括集中式优化和分布式优化两大类。集中式优化方法从全局角度出发,通过对微网群系统的优化目标和相关运行约束整体建模,并利用遗传算法 [3] [4] 、粒子群算法 [5] [6] 和差分进化算法 [7] 等进行集中求解,实现了系统的全局最优。集中式优化方法需要聚合各微网的所有状态信息,无法保护各微网的数据隐私,同时在计算内存和通信带宽的限制下,求解效率难以满足实时性的要求。因此不少研究采用目标级联法 [8] 、ADMM [9] 等分布式方法进行求解,有效保护了各微网的内部信息,但在迭代过程中需要频繁交换边界变量,不仅导致计算效率受限,而且严重依赖于通信链路可靠性。
此外,以上集中式和分布式方法的实现,需要系统的精细化建模以及源荷的准确预测支撑,难以处理源荷的随机波动问题。因此不少学者将目光转向数据驱动方法,开始研究基于深度强化学习的优化方法。文献 [10] 采用了Q学习方法求解微网群调度优化问题,但由于需要对将连续变量离散化,随着变量增多存在维数爆炸的问题。文献 [11] 针对区域综合能源系统,采用DDPG方法求解决策问题,并通过算例验证了所提方法的有效性,该方法无需对动作和状态离散化,可针对连续空间进行决策。文献 [12] 计及源荷的不确定性,将每个节点作为智能体,并通过差分进化策略调整各个智能体的策略。文献 [13] 则针对单个电热联合系统,采用MADDPG方法求解优化策略,通过算例验证了方法的有效性和优越性。以上研究对深度强化学习在电力系统优化领域的应用进行了探索,并验证了其有效性和优越性,然而却未涉及微网群的调度优化问题。在微网群系统中,众多设备大大增加了动作探索的难度,导致收敛速度变慢,且难以探索到最优解,严重影响系统经济运行。
因此,本文在上述研究的基础上,对热电联供型微网群优化任务进行分解,提出一种双层强化学习优化方法。首先,建立了热电联供型微网群的模型;随后进一步设计了热电联供型微网群双层强化学习优化框架,并基于该框架提出了热电联供型微网群双层强化学习优化方法;最后通过算例分析验证了本文方法的有效性和优越性。
2. CHP型微网群系统经济调度模型
2.1. 微网群系统结构
本文的研究对象为CHP型微网群系统,微网内部主要有微型燃气轮机、蓄电池、燃气锅炉、风机、分布式光伏等设备。CHP型微网群系统的结构及能量流动关系如图1所示。

Figure 1. Structure diagram of CHP multi-microgrid system
图1. CHP型微网群系统结构图
2.2. CHP型微网群系统经济调度模型
2.2.1. 目标函数
微网群系统协同优化问题以调度周期
内所有
个微网的总运行成本最小为优化目标:
(1)
式中,
为天然气价格;
为在t时段微网i的MT输出电功率;
、
分别为在t时段相邻微网间的电能交易价格以及微网与配电网之间电能交易价格;
、
分别为在t时段微网i与微网j之间以及微网i与配电网之间的交互电量。
2.2.2. 约束条件
1) 能量平衡约束
微网群系统内的热、电负荷与出力应满足实时平衡约束。
(2)
(3)
式中
为微网i内MT在t时段的余热烟气热量;
为微网i内GB在t时段输出的热功率;
为微网i内MT在t时段的发电功率;
、
分别为微网i在t时段内风电、光伏出力;
、
分别为微网i内蓄电池的充、放电功率;
、
分别为在t时段微网i的热负荷和电负荷。
2) 微型燃气轮机运行约束:
(4)
式中,
、
分别为燃气轮机出力的上、下限。
3) 燃气锅炉运行约束:
(5)
式中,
、
分别为燃气锅炉出力的上、下限。
4) 储能的运行约束:
(6)
(7)
(8)
式中,
、
分别为蓄电池荷电状态的上、下限;
为表示蓄电池在t时段的充放电状态系数。
5) 功率交互约束:
(9)
(10)
式中,
、
分别为微网i与配网交互功率的上、下限。
、
分别为微网i与微网j交互功率的上、下限
3. 微网群系统双层强化学习模型
3.1. 微网群系统双层强化学习优化框架
强化学习问题通常由几大基本要素组成,分别是动作空间、状态空间、回报以及转移概率。强化学习方法通过和环境的不断交互更新策略,使策略趋于最优。通过对微网群优化问题进行分析可知,微网群系统中各微网在空间上的耦合是通过相邻微网间的交互功率实现的,通过将交互功率等效为虚拟的可控负荷或可控电源,可将微网群优化问题分解为若干个微网自治优化子问题;同时,由于储能的存在,各时间断面具有耦合特性,储能策略将影响未来时刻的能量状态,具有较强的时间关联性,且其收益具有明显的滞后性;而其余分布式电源只需基于当前时刻的状态信息即可得出最优动作。
因此,本文提出一种微网群系统双层优化框架,将CHP型微网群优化问题分解为上下两层求解,上层模型制定各微网间的功率交互策略以及微网内部的储能优化策略;下层各微网则基于上层策略完成内部分布式电源出力的自治优化,同时向上层反馈优化目标值指导上层策略更新,利用上下层的协同实现微网群系统的全局优化。
通过上述双层框架,不仅将CHP微网群优化问题在空间上解耦,分解为若干个微网独立并行求解,同时也将各微网自治优化问题分解为多个单时间断面优化问题,可实现快速并行求解,同时各微网只聚合自身状态信息进行自治优化,无需额外的信息交互,有效保护了各微网内部数据隐私。由于强化学习方法为基于无模型的数据驱动方法,其自适应能力较强,且其决策充分考虑收益的滞后性,以使得整个时间序列下的收益最大化,本文上层策略由强化学习智能体给出;下层模型为各微网的单时间断面自治优化问题,规模较小,采用数学规划求解器进行求解,同时聚合优化目标值用于评价上层策略优劣,指导上层策略更新,保证各设备运行约束得到满足,避免了上层智能体模型奖惩函数的复杂设计。微网群系统双层强化学习框架如图2所示。
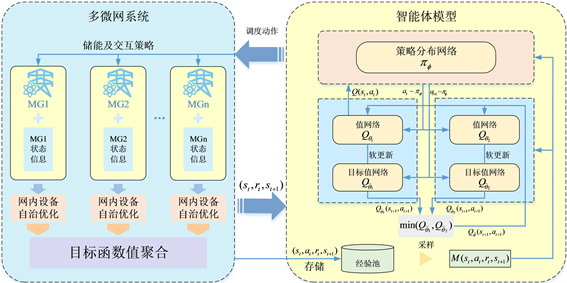
Figure 2. Schematic diagram of two-layer reinforcement learning framework for CHP multi-microgrid
图2. CHP型微网群系统双层强化学习示意图
3.2. 上层智能体模型
强化学习问题可描述为一个马尔科夫决策过程,由状态空间S、动作空间A、奖励函数R以及状态转移概率P组成。智能体基于环境状态选取相应的动作,该动作作用于环境使得环境状态发生改变,并由环境向智能体反馈奖励信号指导智能体的策略更新,通过智能体和环境的不断交互学习得到最大化奖励的序列动作。本文采用基于AC框架的最大化熵强化学习算法——柔性行动器判别器(Soft Actor Critic, SAC)算法构建上层模型,SAC通过引入熵项增强探索性,以提升算法的收敛速度和鲁棒性,可在复杂环境中为微网群系统提供有效的优化策略。
3.2.1. 智能体状态空间
智能体的状态空间用于表征CHP微网群的状态,是智能体决策的基础。本文模型的状态空间包括各微网的可再生能源预测出力、储能荷电状态、电价以及热、电负荷功率:
(11)
式中,
为风力发电预测出力;
光伏发电预测出力功率;
为储能的荷电状态;
为分时电价信息;
为热负荷预测功率;
为电负荷预测功率。
3.2.2. 智能体动作空间
智能体的动作空间即为优化问题中的优化变量,即联络线功率和蓄电池充放电功率:
(12)
式中,
为相邻微网间的交互功率;E为储能荷电量。
3.2.3. 智能体奖励(惩罚)函数
奖励函数是智能体基于当前环境状态选择对应动作作用于环境后反馈的奖励信号。奖励函数用于指导智能体策略的趋优更新,通过持续的学习使得策略的累计奖励最大化。与传统强化学习方法旨在最大化累计奖励不同,本文设置智能体在每一步都会获得与该步的策略熵成正比的奖励,通过引入熵项可以增强强化学习在策略寻优过程中的探索性,加快训练速度的同时也提升了算法的鲁棒性,防止策略过早收敛到局部最优,提高算法寻优性能。因此本文所提强化学习的最终目标为使累计奖励最大的同时,保证策略的熵最大化:
(13)
式中,
为当前优化策略;
为奖励的折扣因子;r为奖励函数;
为t时间断面的状态;
为t时间断面的动作;
为温度系数(
),用于确定策略熵项相对于奖励重要性的比重;H为在状态
下策略采取动作的熵,其计算方式如下:
(14)
在上层的模型中,奖励函数包含微网群优化目标以及动作约束越限惩罚两大类。
1) 微网群优化目标:
(15)
本文选取优化目标为运行成本最小,故式中
为微网群系统在t时段的综合运行成本,由下层模型自治优化后向上层传递。
2) 动作约束越限惩罚:
动作约束越限惩罚用于满足决策动作的相关约束,其中储能的运行约束包括荷电量状态约束(16)、充放电功率约束(17)、调度周期始末能量平衡约束(18):
(16)
(17)
(18)
式中,
、
分别为蓄电池荷电状态的上、下限;
、
分别为蓄电池最大充放电功率;
为表示蓄电池在t时段的充放电状态系数。
各微网的功率交互需要满足上下限约束:
(19)
式中,
、
分别为微网i与微网j交互功率的上、下限。
对于式(17),通过对动作空间大小进行限制即可满足约束。对于式(16)、(18),添加以下惩罚项以保证动作满足约束:
(20)
(21)
式中,
、
为惩罚系数。
因此,最终智能体的奖励函数如下所示,由于智能体以最大化奖励为目标进行探索,取相反数:
(22)
3.2.4. 智能体网络构建
SAC算法是基于AC框架的强化学习方法,其网络结构由Q函数网络和策略分布网络构成,本文采用神经网络参数化Q函数和策略分布,通过交替优化的方式来优化两个网络 [14] 。
柔性Q函数的网络参数可通过最小化贝尔曼残差的方式训练得到:
(23)
式中,
为Q函数网络的参数,
为目标Q函数网络的参数,通过式(24)更新,其中
为软更新系数。为增强网络训练速度和稳定性,本文引入两个相同结构的Q函数网络,选择其中更小的值作为目标Q网络的Q值以增强训练过程的稳定性。
(24)
策略分布网络的参数
通过最小化其KL散度更新:
(25)
此外,温度系数应根据策略的探索程度自动调整,通过最小化一下损失函数自动更新:
(26)
式中,
为表示最小期望熵的超参数。
3.3. 下层微网自治优化模型
下层模型为各个子微网以上层策略为约束的微网自治优化模型,利用上层给出的微网交互策略和储能策略,下层的微网群优化问题不仅实现微网与微网之间的独立求解,同时也分解为多个单时间断面的优化问题。下层各个微网可基于自身微网的状态信息,采用数学规划求解器快速并行求解网内设备的最优出力策略,并在训练过程中聚合各个微网的目标函数值向上层反馈以指导上层策略更新。本文以CHP微网的经济型最优为目标,微网运行成本包含了燃气成本、相邻微网交互成本以及配网交互成本,下层自治优化模型如式(27)所示
(27)
式中,
为天然气价格;
为在t时段微网i的MT输出电功率;
、
分别为在t时段相邻微网间的交易电价以及微网与配电网之间交易电价;
、
分别为在t时段微网i与微网j之间以及微网i与配电网之间的功率交互大小。
4. 算例验证与分析
4.1. 算例设置
本文采用包含三个CHP型微网的微网群系统进行算例验证分析 [15] 。图3给出了微网1日前源荷预测功率。相邻微网之间的购售电价为向配网售电价格。微网内相同类型的设备参数及其他算例设置参考文献 [15] 。

Figure 3. The prediction of source and load in microgrid 1
图3. 微网1内源荷预测功率
4.2. 模型收敛性分析
针对上述算例,采用本文所提方法进行训练,训练过程中的奖励函数曲线如图4所示,从图中可以看出,本文方法在训练1600轮左右时收敛。在探索初期由于随机动作导致的奖励较低,随着训练过程的持续,智能体不断更新策略,奖励值逐渐升高,最终稳定不再上升,模型收敛较迅速且稳定。
此外图5给出了算法中未加入熵项的情况下训练过程中的运行成本曲线作为对比,从图中可以看出,无熵项SAC算法易陷于局部最优,而基于最大熵框架的SAC训练过程中的收敛速度和精度均优于无熵项SAC。这是由于在算法目标中加入熵项后可以提升强化学习算法的探索能力和鲁棒性,因此添加熵项有助于算法跳出局部最优寻找全局最优策略。
4.3. 调度优化结果分析
对训练好的双层强化学习模型进行测试得到微网群系统的优化调度结果。图6给出了24 h内的储能策略以及电价变化情况,从图中可以看出,模型给出的储能策略为:在电力需求低谷时即低电价时段充电储能,能量来源主要为向配网购电以及富余的可再生能源;在电力需求高峰时即高电价时段放电,用于供给系统内负荷以及向配网售电,通过电价引导储能策略的变化,以减少系统的调度成本。

Figure 6. The SOC of storage in microgrid 1
图6. 微网1内储能荷电状态变化情况
微网1内的热能流动情况如图7所示。从图7可以看出,在0:00~7:00以及23:00~24:00时段,此时向配网购电电价较低,微型燃气轮机不启动,微网1内的热负荷由燃气锅炉消耗天然气供给。在其余时段,用电负荷增加,电价开始升高,此时微型燃气轮机启动,通过消耗天然气进行热电联供从而减少向配网购电的成本,该时段的热负荷由燃气轮机运行过程中的余热供给。
图8给出了微网1内的电能流动情况,由图可知,此外,在23:00~7:00时,此时为谷电价时段微网1内的电负荷由新能源及向配网购电供给。在7:00~23:00时,此时电价较高,微型燃气轮机启动运行,
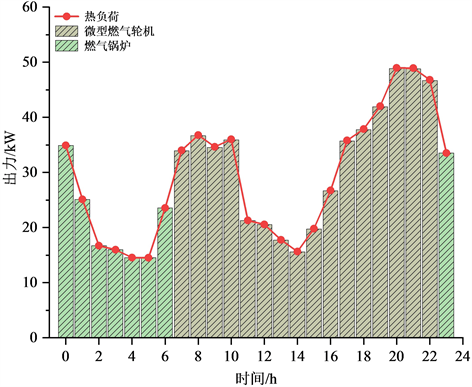
Figure 7. The flow of thermal energy in microgrid 1
图7. 微网1热能流动情况

Figure 8. The flow of electric energy in microgrid 1
图8. 微网1电能流动情况
以供给系统内的电负荷。微网1是一个典型的新能源过剩的微网,其负荷需求在大部分时间均低于微网内可再生能源。因此微网内的可再生能源在供给微网内电负荷之外,还通过供蓄电池充电和向配网及相邻缺电微网售电的方式消纳。
4.4. 对比分析
4.4.1. 单层强化学习对比分析
本文方法通过对CHP型微网群系统优化任务进行分解,将部分变量在下层自治优化模型中利用求解器求解,有效减少了上层智能体的动作空间维数,同时也简化了奖励函数的设计难度,降低了智能体的策略探索难度。为验证本文方法相比传统强化学习方法的优越性,将本文方法和单层强化学习方法SAC进行对比。两方法在训练过程中的运行成本曲线如图9,由图不难看出,SAC方法在大约7200轮左右时收敛,而本文方法大约在1900轮左右即收敛;并且SAC方法仅探寻到局部最优解,收敛到的运行成本远高于本文方法,这是由于微网群中的变量众多,探索难度较大,传统的强化学习方法难以探索到较优的策略。两种方法的对比结果如表1所示,验证了本文方法的在收敛速度和精度上的优越性。
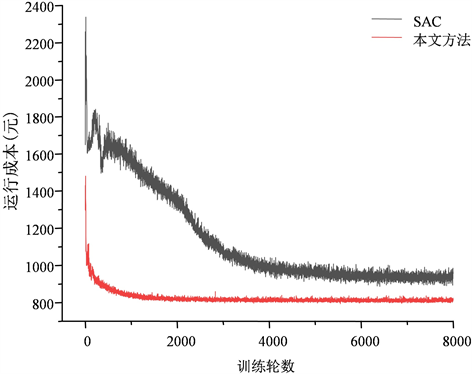
Figure 9. The operational cost curves in training process of two methods
图9. 两方法训练过程中的运行成本曲线

Table 1. Comparison of SAC and the method in this paper
表1. SAC与本文方法比较
4.4.2. 集中式优化对比分析
为验证本文所提方法的有效性,利用商业求解器CPLEX收集各微网的全局信息进行集中求解,集中求解得到的结果即为CHP微网群系统的全局最优解。两种方法给出的微网群系统与配网的购售电量如图10所示。从结果中可以看出本文方法给出的配网购售电量与集中式优化给出的最优解基本一致,存在较小出入的主要原因是储能的存在使得策略具有一定灵活性,两种方法的最终运行成本如表2,本文方法与基于全局完美预测信息的最优解差距在0.04%左右,验证了本文所提方法的有效性。而集中式优化需要收集全局信息进行求解,求解较为困难,求解时间为378.277秒,难以满足实时优化的要求,而本文方法在0.01秒左右即可完成策略生成,可实现在线优化。
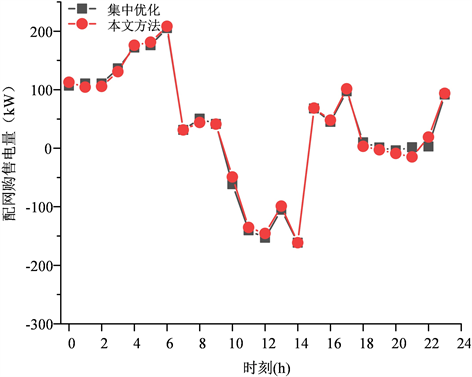
Figure 10. Comparison of electricity purchase/sale strategies of distribution network of two methods
图10. 两方法的配网购售电策略对比
Table 2. Comparison of centralized optimization and the method in this paper
表2. 集中式优化与本文方法比较
4.5. 应对源荷随机性分析
强化学习模型基于数据驱动,通过历史数据的反复训练具有良好的鲁棒性,训练完成的模型只需读取状态数据即可给出调度结果,满足在线优化的要求。为验证本文所提方法应对源荷随机性的能力,选取源荷不同程度波动场景对模型进行测试。
Table 3. Comparison of test results under different volatility levels
表3. 同波动性水平下测试结果比较

Figure 11. Comparison of costs in different scenarios
图11. 不同场景下成本比较
图11为波动性水平在10%时,本文方法求解的结果与最优解的对比情况。表3给出了不同波动性水平下本文方法与最优解的差距。从图表中可知,当源荷波动性在5%、15%、20%时,本文方法与基于完美预测信息的最优解差距分别在0.03%、0.18%、0.21%左右,验证了本文方法具有良好的鲁棒性,可根据源荷随机波动动态调整。
5. 结论
本文面向CHP型微网群系统,设计了一种基于双层强化学习的调度优化方法,该方法将CHP型微网群系统优化任务分解为上下两层,上层由智能体给出各微网的交互策略和蓄电池充放电策略,下层各微网基于上层策略利用求解器自治优化,通过上下层的协同完成系统的全局优化,缩减了智能体的动作空间维数,并简化了奖励函数的复杂设计,提升了收敛精度和收敛速度。各微网之间不进行信息交互,只向智能体上传源荷预测出力等关键信息,有效保护各微网的数据隐私。通过本文方法与传统单层强化学习和传统集中式优化方法对比,验证了本文方法基于局部信息即可得到与全局最优解趋于一致的结果,且在收敛速度和精度上都具有明显的优越性。